
0
წაკითხვა
0
კომენტარი
0
გაზიარება
მონაცემთა ანალიზი და ქართული არჩევნები
სტატია თავდაპირველად გამოქვეყნდა ჩემს ბლოგში Medium-ზე.
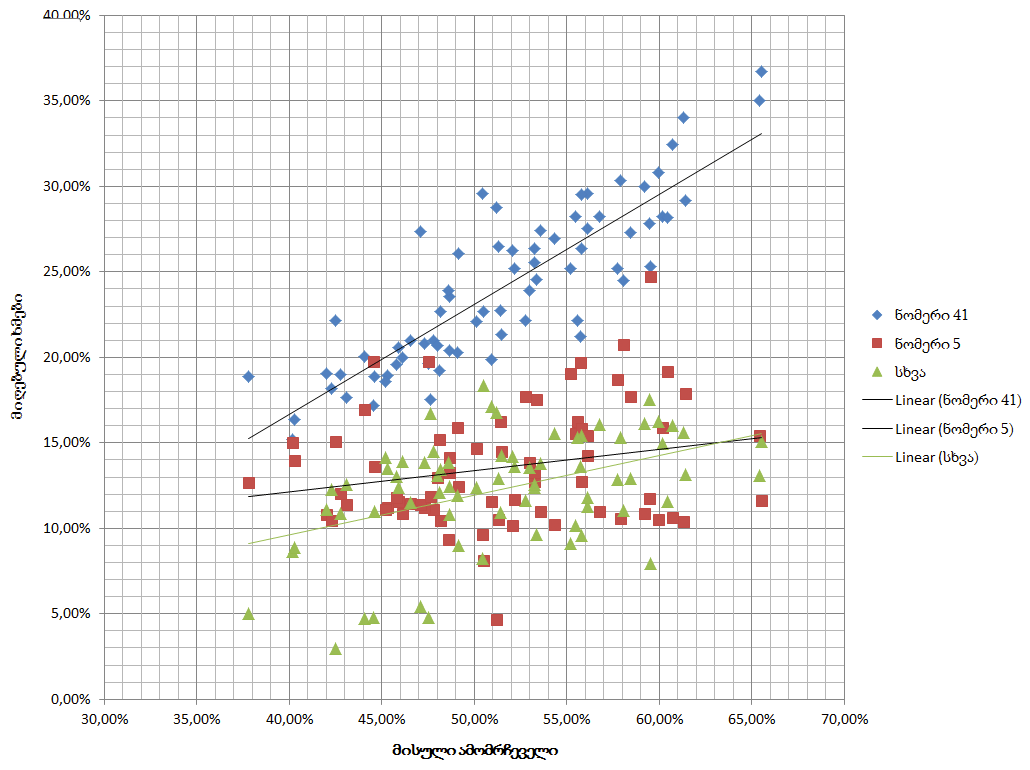
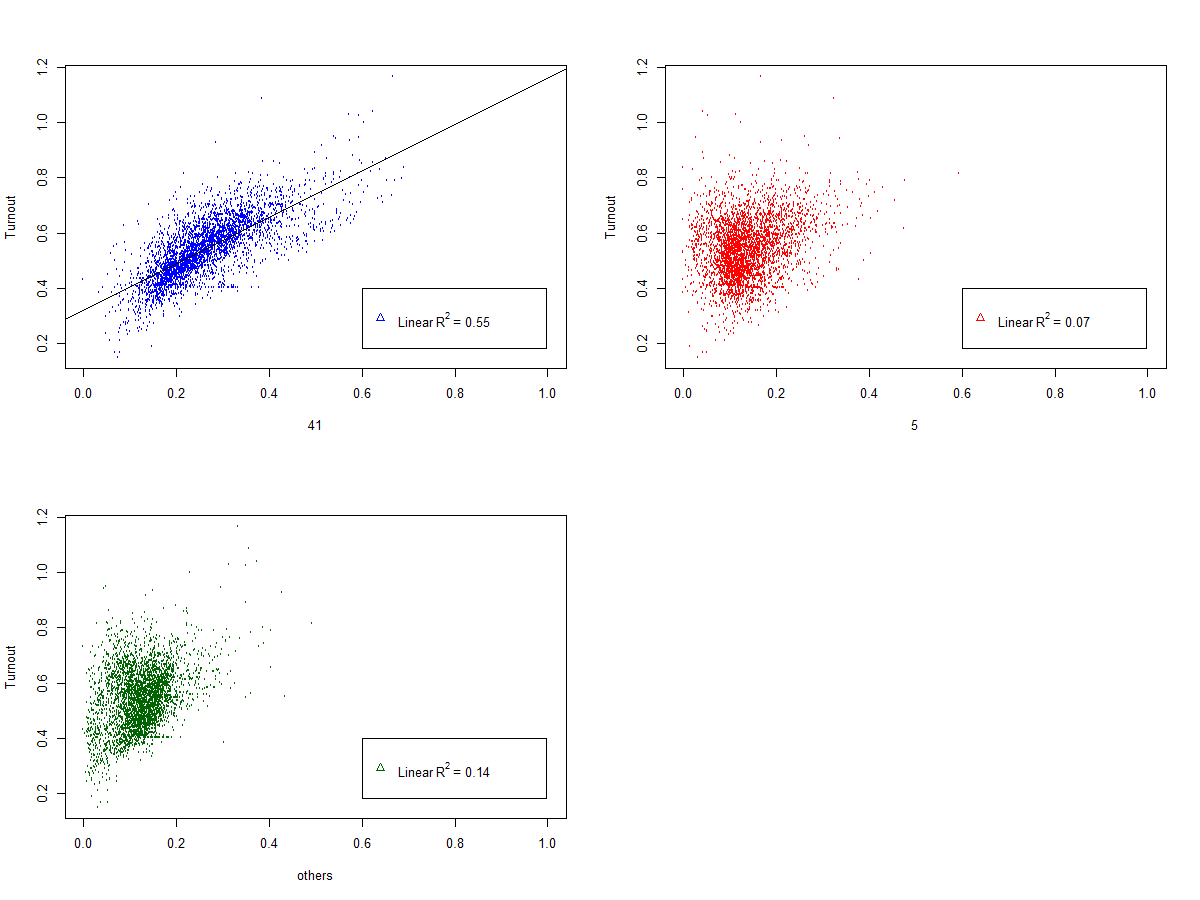
მთავარი რამ ამ ამბავში, ეს გრაფიკია, სადაც 2016 წლის 8 ოქტომბრის არჩევნებზე, პარტიების მიერ მიღებული ხმები ამომრჩეველთა აქტივობის კონტექსტში ჩანს. იმ ოლქებში, სადაც უფრო მაღალი აქტივობა იყო, ხმას უფრო მეტად ქართულ ოცნებას (ნომერ 41-ს) აძლევდნენ, რაც, არაბუნებრივია. მოსალოდნელი თანაბარი განაწილების ნაცვლად, მკაფიო კორელაცია შეიმჩნევა.
თუ მხოლოდ ამ გრაფიკის ინტერპრეტაცია გაინტერესებთ, გადახტით ქვეთავზე „შედეგები“. ხოლო თუ მსუბუქ ტექნიკურ გადახვევაზეც არ იტყოდით უარს, განაგრძეთ კითხვა:
პროგრამირების ენა R
R ერთ-ერთი ძველი პროგრამირების ენაა. K და L-ის მსგავსად, ისიც ეგზოტიკური ენების რიცხვს მიეკუთვნება. ბოლო ორისგან განსხვავებით პირველის გამოყენება რამოდენიმეჯერ მომიხდა.
თავს არ შეგაწყენთ 24 წლის წინანდელი სტატისტიკის კომიტეტის, 15 წლის წინანდელი საკრედიტო ბარათების მაქინაციების დევნის და სხვა მსგავსი ამბების მოყოლით. უბრალოდ გეტყვით, რომ R მძლავრი ინსტრუმენტია დიდი მონაცემების სტატისტიკური ანალიზისა და ვიზუალიზაციისათვის.
ფეისბუკის ფიდში RStudio 1.0-ის გამოსვლის შესახებ ნიუსი ვნახე და ვცდი-მეთქი, ვიფიქრე. წესი მაქვს: პროგრამირების ენას რომ ვარჩევ, აუცილებლად რაიმე სასარგებლოს (ან, მინიმუმ, მეტნაკლებად რეალისტურს) ვაკეთებ. არ მიყვარს getting started-ზე გაჩერება.
ამას წინ, ორ სხვადასხვა რუსულენოვან სტატიას წავაწყდი. ერთში რუსეთის არჩევნების შედეგების სტატისტიკური ანალიზი იყო, მეორეში — რუსულ ანალიზზე დაყრდნობით, ქართულის. ამიტომ ვიფიქრე, რომ მეც მეცადა.
მოკლედ, ვითამაშე. რაღაც ეფექტები მართლაც დავინახე. მერე გადავწყვიტე, დანახულის ნაწილი რაც შეიძლება მარტივად, ჩვეულებრივი Excel-ის მომხმარებლისათვის გასაგებად გადმომეცა.
Excel-დან დანახული არჩევნები
ვიცი, რომ ცხონებული ბენდუქიძის და გირჩების გარდა საქართველოში ციფრები და პროცენტები დიდად არავის ეხატება გულზე. მაგრამ, წარმატებული ქვეყნები და კომპანიები, დიდ სარგებელს ნახულობენ ხოლმე მხოლოდ რიცხვების სტატისტიკური ანალიზით.
სადაზღვევო კომპანიები, ბანკები, მაღაზიების ქსელები და ბირჟები მანიპულაციების აღმოსაჩენად დიდწილად მონაცემების სტატისტიკურ ანალიზს ეყრდნობიან.
მაგალითისათვის: თუ ყველა ფილიალში გაყიდული საპარსი ქაფების და საპარსი პირების რაოდენობას შორის შეფარდებაა 1/10 და მხოლოდ ერთ ფილიალშია — 1/5, ესე იგი, სავარაუდოდ, ამ ფილიალში საპარსის პირებს იპარავენ.
რისი დანახვა შეიძლება მარტივად, მხოლოდ Excel-ით შეიარაღებული თვალით, 2016 წლის არჩევნების მონაცემებიდან, პირველივე შეხედვით?
ქვემოთ ნაბიჯ-ნაბიჯაა აღწერილი, თუ რა გავაკეთე და რა შედეგი მივიღე.
სტატიის ბოლოს კი ბმულია გადმოსაწერ ფაილზე და მითითებულია „ნედლი“ მონაცემების წყაროები.
რა გავაკეთე?
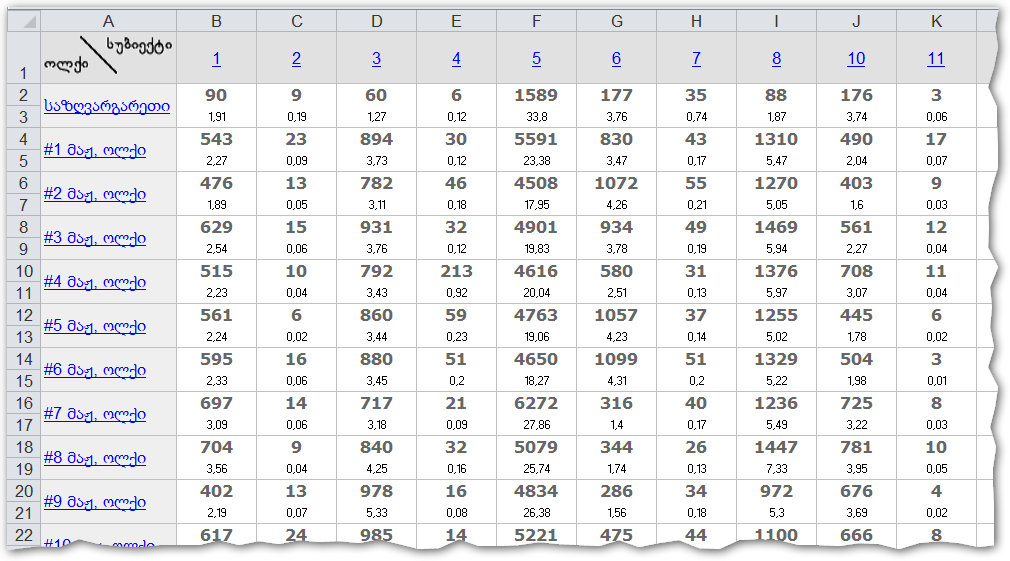
1. ჩავყაროთ მიცემული ხმების რაოდენობა ოლქების მიხედვით Excel-ში:
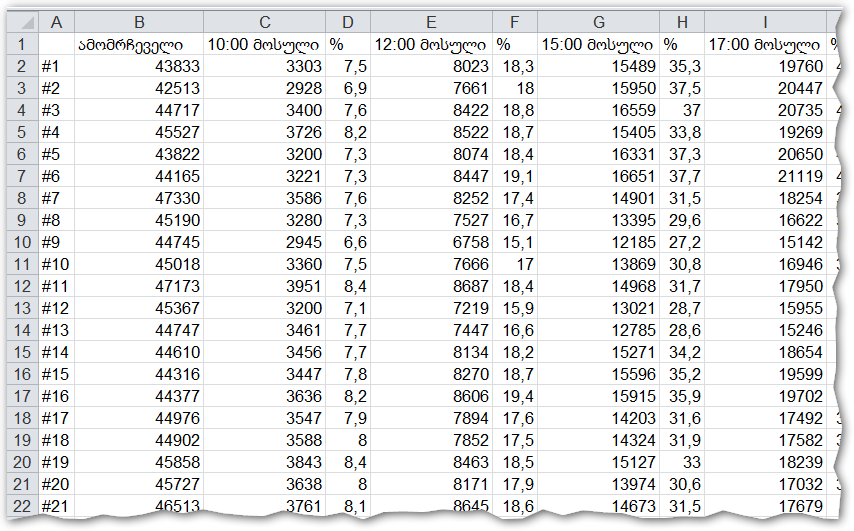
2. დავუმატოთ კვლავ ცესკოს საიტიდან მოპოვებული ამომრჩეველთა აქტივობის სტატისტიკა, ასევე ოლქების მიხედვით:
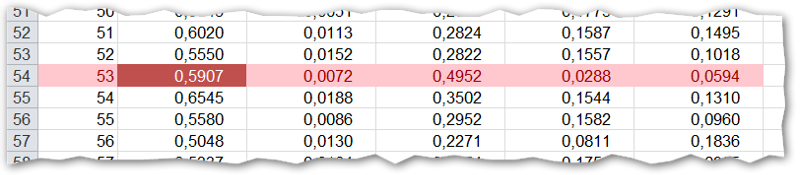
3. გამოვთვალოთ შემდეგი ფარდობითი მაჩვენებლები ოლქების მიხედვით:
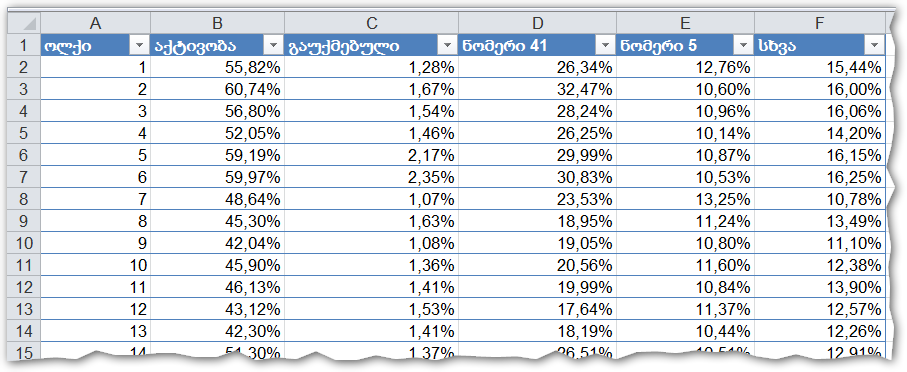
შემოვიღოთ აღნიშვნა S = დარეგისტრირებული ამომრჩევლების რაოდენობა.
აქტივობა = ისედაც გასაგებია, მოსულების შეფარდება დარეგისტრირებულებთან. ანუ, (მოსულები) / S
ფარდობითი გაუქმებული = (მოსულები – ჯამში მიცემული ხმები) / S
ფარდობითი ხმები = (მიღებული ხმების რაოდენობა) / S
სიმარტივისთვის, ყველაფერი დარეგისტრირებული ამომრჩევლის პროცენტშია. ანუ, მაჩვენებელი 15,44% სვეტში "სხვა" ნიშნავს, რომ დარეგისტრირებული მომხმარებლების 15,44-მა პროცენტმა ხმა მისცა ნომერ 5 და ნომერ 41-სგან განსხვავებულ, მესამე პარტიას.
4. ამოვყაროთ აშკარა ამოვარდნები
მაგალითად, ამ ოლქში გაუქმებული ბიულეტენების რაოდენობაა ძლიერაა გადახრილი:

აქ კი, თითქმის ყველა გამოცხადებულმა ნომერი 41 შემოხაზა:
5. ავაგოთ Scatter გრაფიკი. x-ღერძზე აქტივობა დავიტანოთ, y-ზე კი, მიცემული ხმების ფარდობითი სიდიდეები:
6. თვალსაჩინოებისთვის, ჩავრთოთ წრფივი გასაშუალოების ვიზუალიზაციაც:
შედეგები?
დავუბრუნდეთ ჩვენს გრაფიკს:
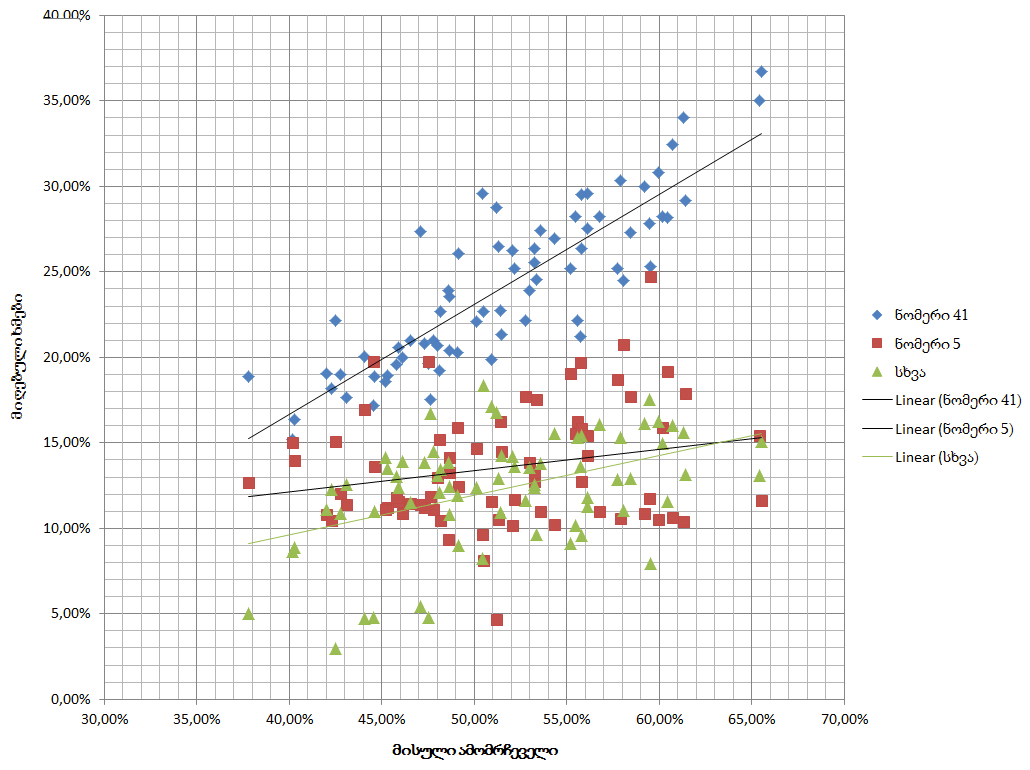
როგორც ამ გრაფიკიდან თვალნათლივ ჩანს, იმ ოლქებში, სადაც უფრო მაღალი აქტივობა იყო, ხმას უფრო მეტად ნომერ 41-ს აძლევდნენ, რაც, არაბუნებრივია.
მოსალოდნელი თანაბარი განაწილების ნაცვლად, მკაფიო კორელაცია შეიმჩნევა. ნომერ 5-ში და “სხვა”-ში კი განაწილება თანაბარია.
დაინტერესებულებს, შეუძლიათ R²-იც გამოთვალონ: ლურჯი ჯგუფისათვის 0,8-ზე მაღალია, დანარჩენი ორი ჯგუფისათვის 0,5-ზე დაბალი. ეს, პირველ შემთხვევაში კორელაციის არსებობას და მეორე შემთხვევაში — თანაბარ განაწილებას კიდევ ერთხელ ადასტურებს.
ცნობილი მანკიერებების გარდა, როგორიცაა ხალხის ძალით მიყვანა და ბიულეტენების ჩაყრა, წელს კიდევ ერთი გაჟღერდა — ეს იყო, ბიულეტენების ძალით "გაფუჭება".
ამ გრაფიკიდან ჩანს რომ რაც უფრო მეტია გაფუჭებული ბიულეტენების რაოდენობა ოლქში, მით ნაკლებია ნომერი 5-ის წილი. ბუნებრივი აქაც თანაბარი განაწილება იქნებოდა. სამწუხაროდ, წითელ ჯგუფში გარკვეული კორელაცია ჩანს, თუმცა R² ცუდია, ამიტომ, დასკვნებს არ გამოვიტან.
ფაილის ჩამოტვირთვა: 2016archevnebi.xlsx
განახლება: კორელაცია უბნების მიხედვით
მას შემდეგ, რაც ამ სტატიამ ქართულენოვან ინტერნეტ სივრცეში გარკვეული პოპულარობა მოიპოვა, გადავწყვიტე მომეპოვებინა უფრო დეტალური ინფორმაცია უბნების მიხედვით, ამჯერად — უბნებისთვის იგივე კორელაციის საჩვენებლად.
ფაილის ჩამოტვირთვა: 2016-elections-bystation-raw.xlsx
ამ ცხრილში თავმოყრილია ინფორმაცია, რომელიც ნაწილობრივ ცესკოსგან გამოვითხოვე (აქტივობა უბნებისა და საათების მიხედვით), ნაწილობრივ კი — წვალებით, HTML-იდან გამოვწოვე.
ცხრილები მოიცავს:
- აქტივობას უბნებისა და საათების მიხედვით.
- რეგისტრირებულ ამომრჩეველთა რაოდენობას უბნების მიხედვით.
- უბნების GPS კოორდინატებს.
- ხმის დათვლის შედეგებს უბნების მიხედვით.
შედეგები მოკლედ:
ანალიზი უბნების მიხედვით დაახლოებით იგივე სურათს გვიჩვენებს.
წყაროები:
- ამომრჩეველთა რაოდენობა ოლქების მიხედვით (ცესკო)
- ხმების დათვლის შედეგები ოლქების მიხედვით (ცესკო)
- აქტივობა ოლქების მიხედვით (ცესკო)
































კომენტარები