როგორ მუშაობს გენიალური ალგორითმი, რომლითაც შაზამი სიმღერებს იცნობს

ფოტო: Real Engineering
ალბათ უმეტესობა თქვენგანს შაზამი ცხოვრებაში ერთხელ მაინც გამოუყენებია.
საკმარისია, აპლიკაციას რაიმე მუსიკა მოასმენინოთ და ის სულ რამდენიმე წამში მსოფლიოში არსებული მილიონობით სიმღერიდან იმ ერთადერთს პოულობს, რომელსაც თქვენ ეძებთ. ეს ერთი შეხედვით შეიძლება მარტივ დავალებად მოგეჩვენოთ, თქვენც ხომ გამოგიცნიათ მეგობრის წაღიღინებული სიმღერა, მაგრამ ყველაფერი ასე მარტივადაც არაა. ჩვენთვის სულ რაღაც რამდენიმე ნოტის გაგებაც კი საკმარისია, რომ ცხოვრებაში გაგონილი ათიათასობით სიმღერიდან ჩვენი საყვარელი ამოვიცნოთ, თუმცა, არ უნდა დაგვავიწყდეს, რომ ჩვენს ტვინში არსებული ის მექანიზმები, რომლებიც ამ "სუპერძალას" გვაძლევს, უაღრესად რთულია და ისინი მილიონობით წლის განმვალობაში მიმდინარე ევოლუციური პროცესების შედეგია.
ამ ყველაფრის 0-ებისა და 1-ების ენაზე გადათარგმნა და კომპიუტერისთვის დავალება კი წარმოუდგენელ გამოწვევას ჰგავს. კომპიუტერებს მუსიკის აღქმა არ აქვთ, მათთვის აღნიშნული დავალების შესრულების ერთადერთი გზა სიმღერების სათითაოდ ერთმანეთთან შედარებაა.
მსოფლიოში არსებული მილიონობით სიმღერიდან სასურველის პოვნა შეგვიძლია თივის ზვინში ნემსის ძებნას შევადაროთ, თანაც, ნემსი რომ თივის ღეროსგან გაარჩიოთ, ამისთვის ნემსის ფოტო თითოეული თივის ღეროს სათითაოდ უნდა შეადაროთ - სწორედ ასე მუშაობენ კომპიუტერები.
2014 წელს მანჩესტერის მეცნიერებისა და ინდუსტრიის მუზეუმმა ჩაატარა კვლევა, რომლის მიზანსაც ყველაზე ადვილად გამოსაცნობი სიმღერის დადგენა წარმოადგენდა. ექსპერიმენტში მონაწილეობა 20 000-მა ადამიანმა მიიღო, რომლებსაც 1 000 სიმღერის ნაწყვეტი მოასმენინეს და გაზომეს, თუ რა დრო სჭირდებოდათ მათ თითოეულის ამოსაცნობად.
შეგიძლიათ თუ არა ქვემოთ მოცემული ნაწყვეტის ამოცნობა?
ეს ჯგუფი Spice Girls-ის Wannabe-ა, რომელმაც კვლევაში პირველი ადგილი დაიკავა. მის ამოსაცნობად კვლევის მონაწილეებს ყველაზე ნაკლები დრო, სულ რაღაც 2,3 წამი სჭირდებოდათ.
ადამიანის ტვინი გარემოში სხვადასხვა კანონზომიერებების ამოცნობაში ძლიერადაა დახელოვნებული - ისეთ გარემოში ყოფნისას, რომელშიც მტაცებლის ხმის ნაადრევად ამოცნობამ შესაძლოა შენი სიცოცხლე გადაარჩინოს, ამ უნარისთვის აუცილებელი მექანიზმები გამუდმებით იხვეწება.
ტვინს გაგებული მელოდიის ამოსაცნობად არ სჭირდება, რომ ის ყველა აქამდე გაგონილ მელოდიას შეადაროს. ამ პროცესის დროს კონკრეტული ნოტები და აკორდები ტვინში უშუალოდ იმ ნეირონებს ააქტიურებს, რომლებიც ასოციაციებთან და მოგონებებთანაა დაკავშირებული.
რა მოხდება, თუ ამავე აკორდებს სხვა ინსტრუმენტზე შევასრულებთ? მაინც შეძლებს თუ არა ჩვენი ტვინი მელოდიის ამოცნობას?
ქვემოთ მოცემულია იგივე ორწამიანი ნაწყვეტი, ამჯერად გიტარაზე.
რა თქმა უნდა, შეძლებთ. ამ შემთხვევაში ნოტები იდენტურია, მაგრამ შეამჩნევდით, რომ ჩანაწერების ჟღერადობა განსხვავდება და ჩვენ ინტუიციით იმასაც კი ვხვდებით, თუ რომელ ინსტრუმენტზეა გაკეთებული ეს უკანასკნელი ჩანაწერი.
როგორ ხდება ეს?
აქ საქმეში ტემბრი ერთვება, რომელიც ყველა ინსტრუმენტს უნიკალური აქვს. ტემბრი არის ის, რაც ფორტეპიანოს ხმას, გიტარის ხმისაგან განასხვავებს. ფორტეპიანო და გიტარა ჰარმონიული ინსტრუმენტებია, ნოტის დაკვრისას გამოცემული ხმა არა ერთი ნოტის სუფთა სიხშირე, არამედ სიხშირეების ერთობლიობაა, რომელიც ნოტის საწყის, ფუნდამენტურ სიხშირესთანაა კავშირში.
ამის უკეთ გააზრებას ქვემოთ მოცემული ჩანაწერით შეძლებთ. პირველი ბგერა ფორტეპიანოზე დაკრული მე-4 ოქტავის დო-ა, შემდეგი ბგერები კი ის სიხშირეებია, რომლებისგანაც თავად ეს დო შედგება.
სიხშირეების ეს ერთობლიობა კი ყველა ინსტრუმენტისთვის უნიკალურია, სწორედ ეს აძლევს ყველა ინსტრუმენტის ხმას ინდივიდუალურ ელფერს.
ჩვენთვის ამ ყველაფრის გარჩევა ადვილია, თუმცა როგორ უნდა გაართვას თავი ამ დავალებას კომპიუტერმა?
შაზამი სიმღერის ამოცნობის პროცესს სამ ძირითად ეტაპად ყოფს.
1. სიმღერის ანაბეჭდის შექმნა
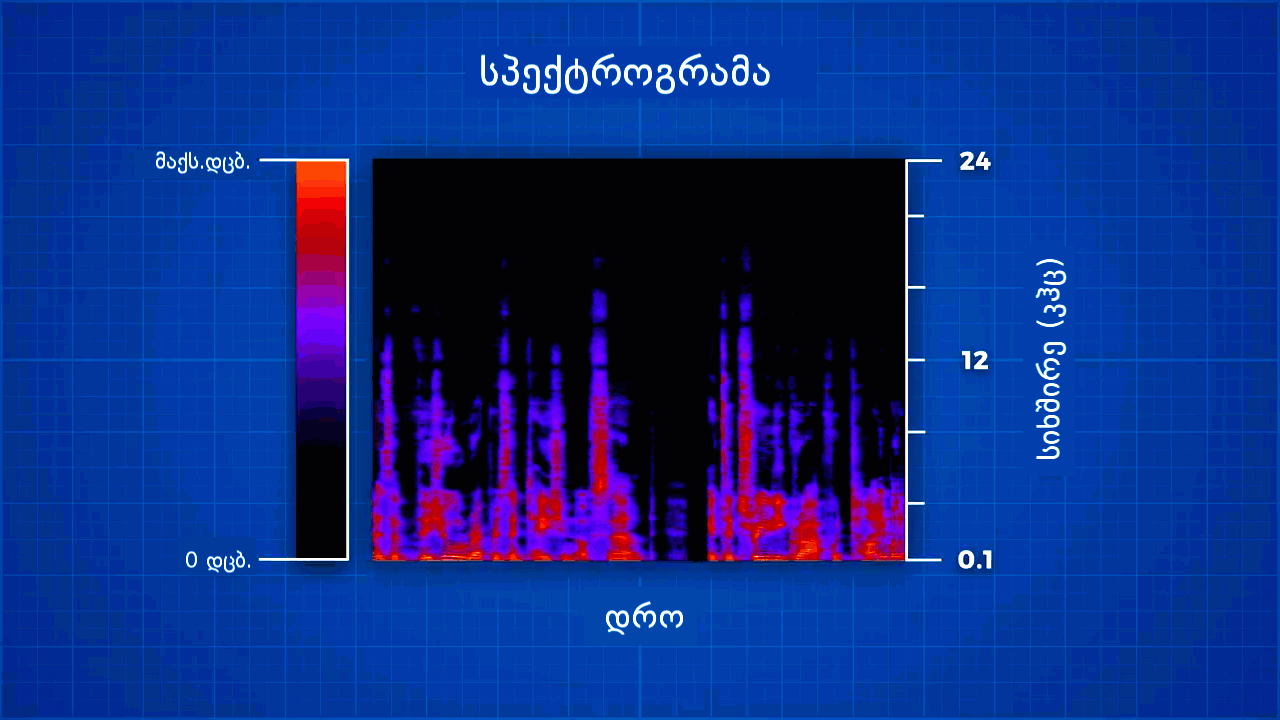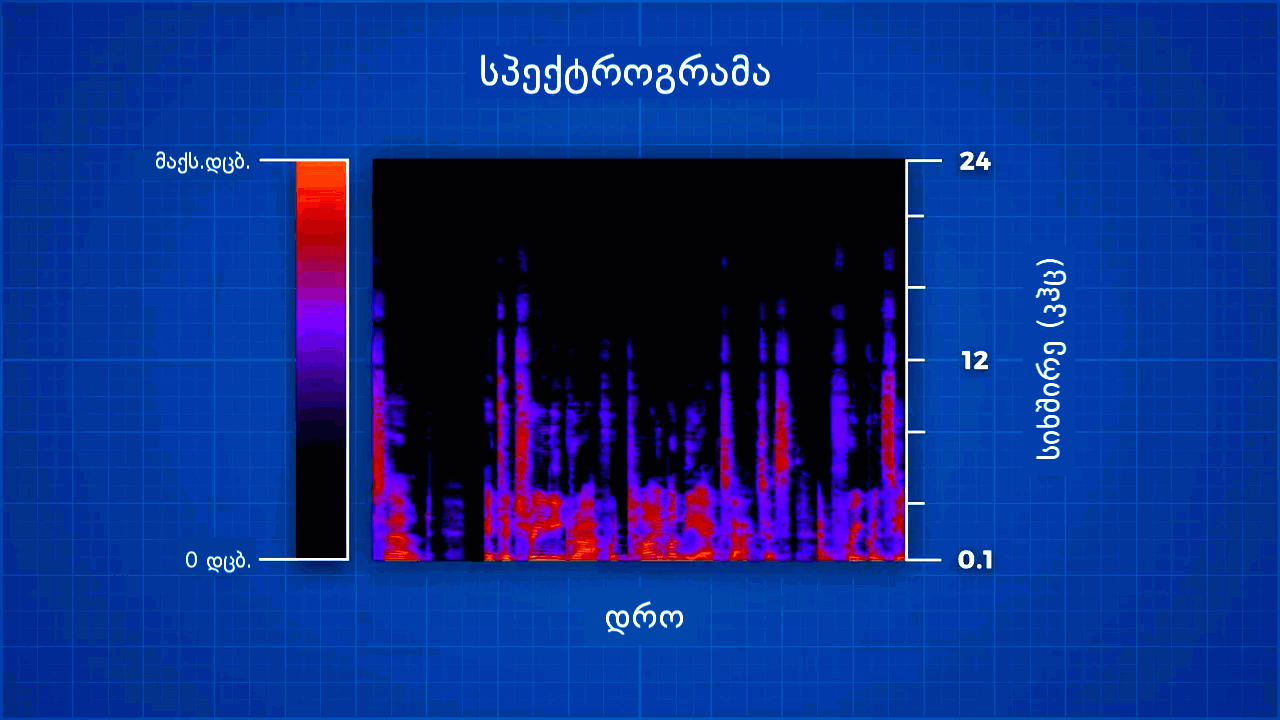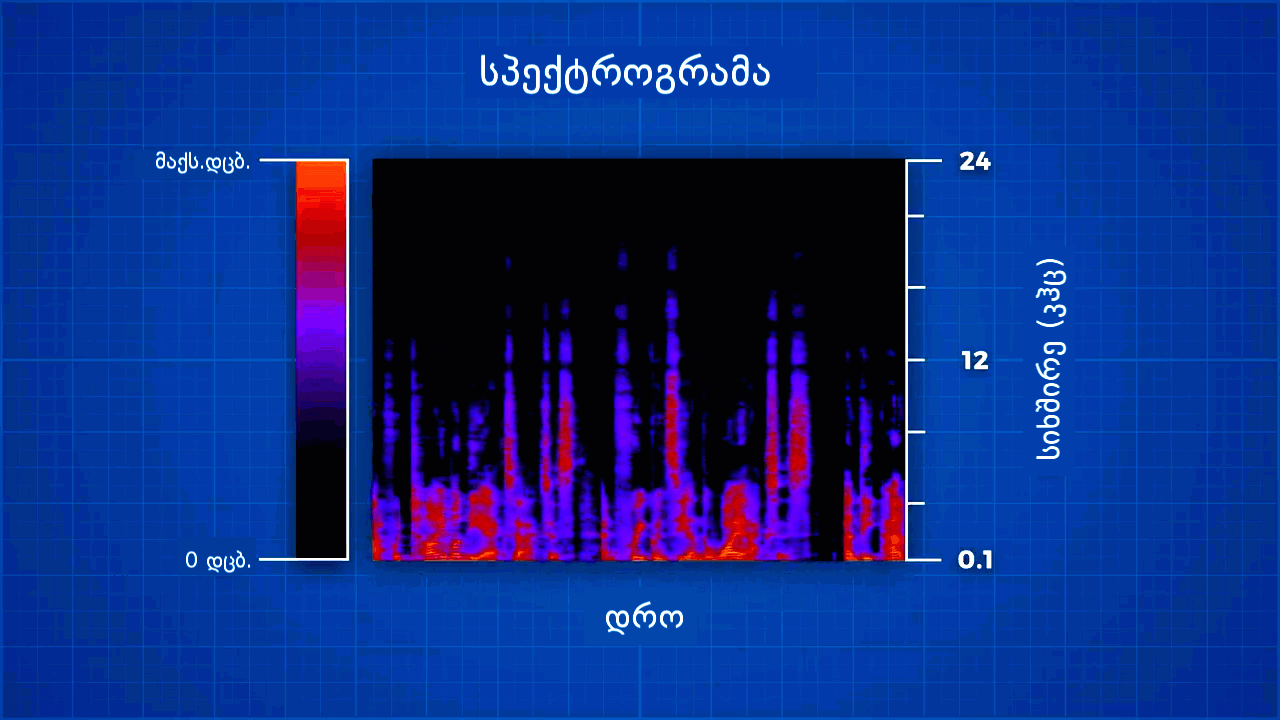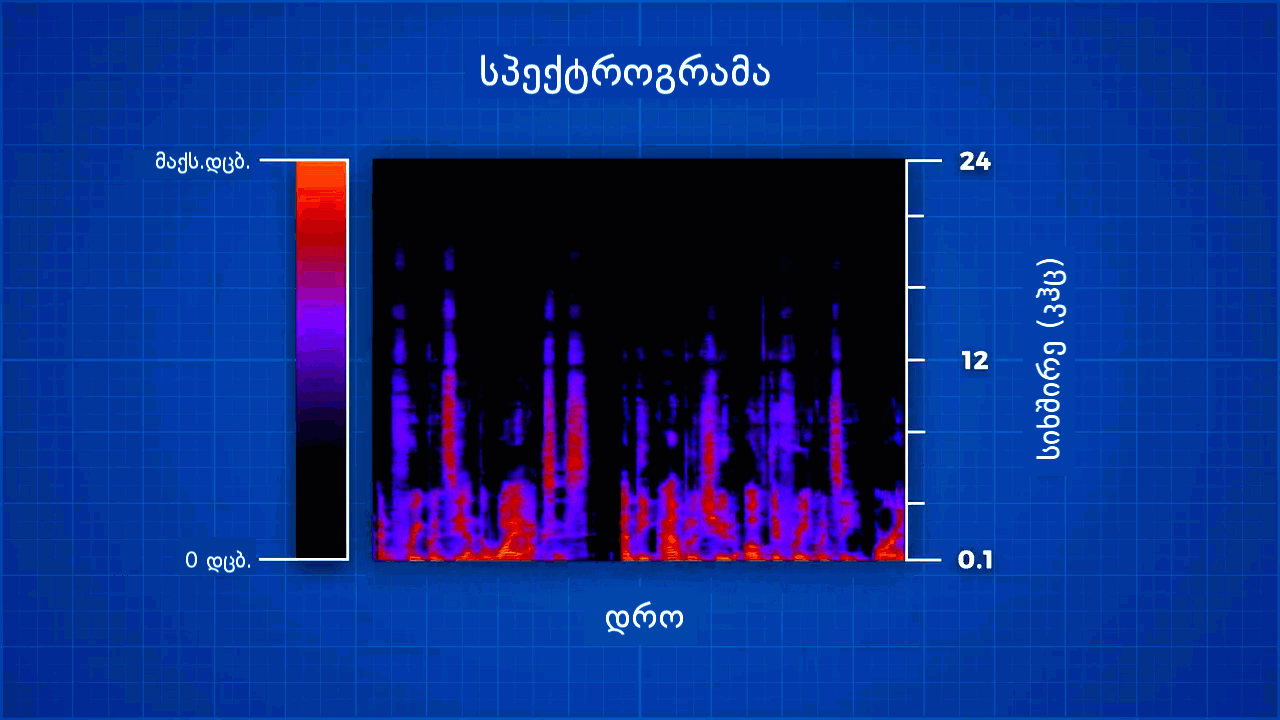
სიმღერის ამოცნობა მიკროფონით ჩაწერილი აუდიო სიგნალის სპექტროგრამის შექმნით იწყება. სპექტროგრამა აუდიო სიგნალში არსებული სიხშირეების ვიზუალური გამოსახვაა. ეს სამგანზომილებიანი გრაფიკია, რომლის x-ღერძზე დრო, y-ღერძზე სიხშირე, z-ღერძზე კი სიგნალის სიმძლავრეა აღნიშნული.
კომპიუტერი მუსიკას ცნობიერად ვერ აღიქვამს, თუმცა ამ სპექტროგრამას კითხულობს. საქმე ისაა, რომ აღნიშნულ სპექტროგრამაში ძალიან დიდი რაოდენობის ინფორმაციაა მოცემული, რომლის დამუშავებასაც დიდი დრო დასჭირდება.
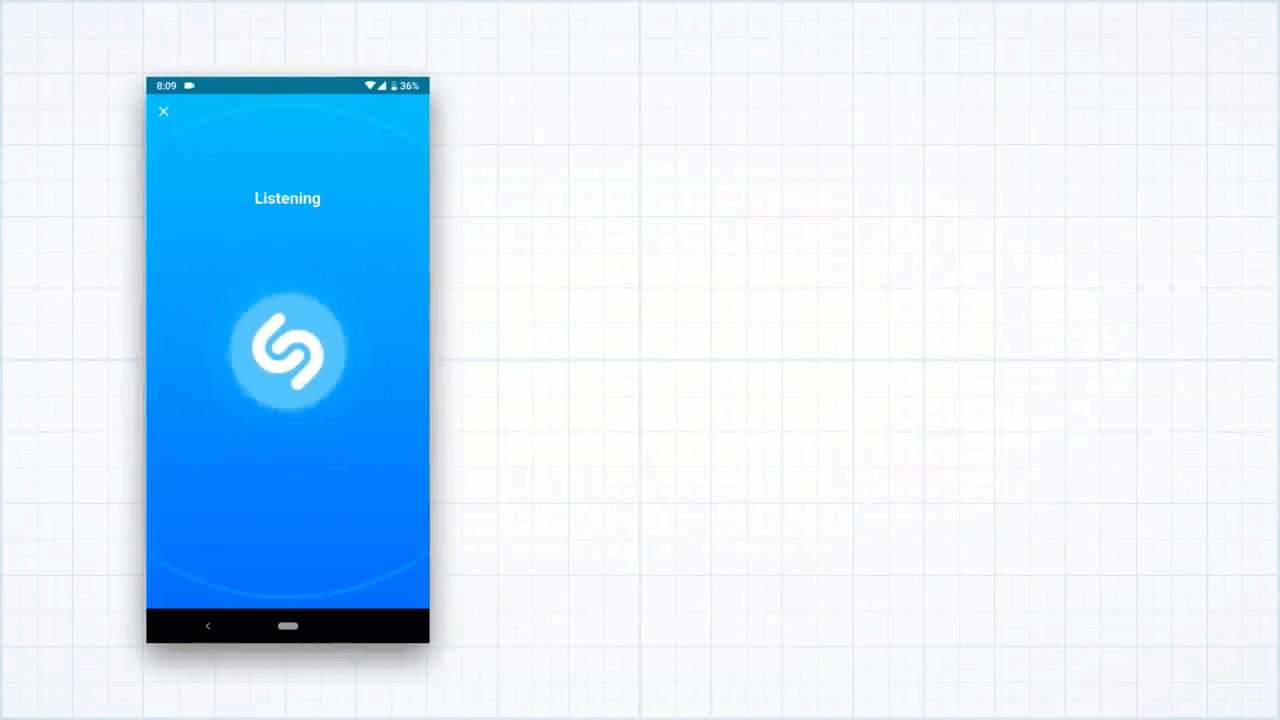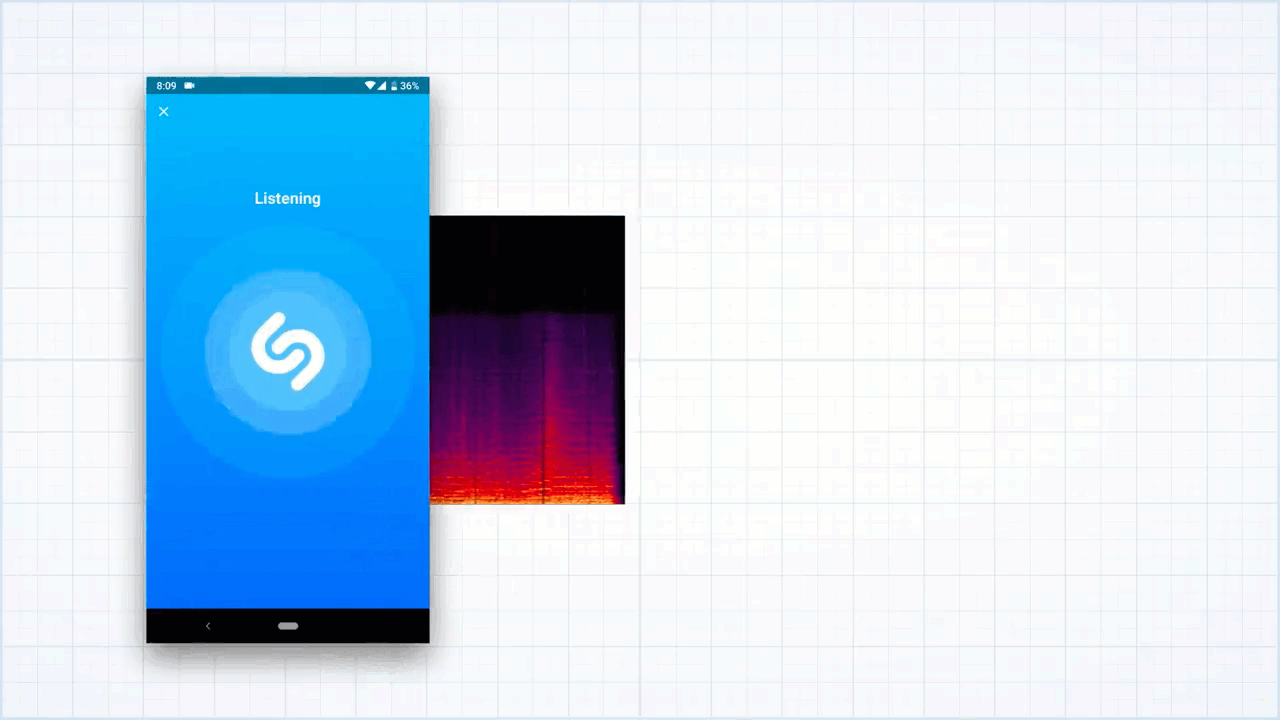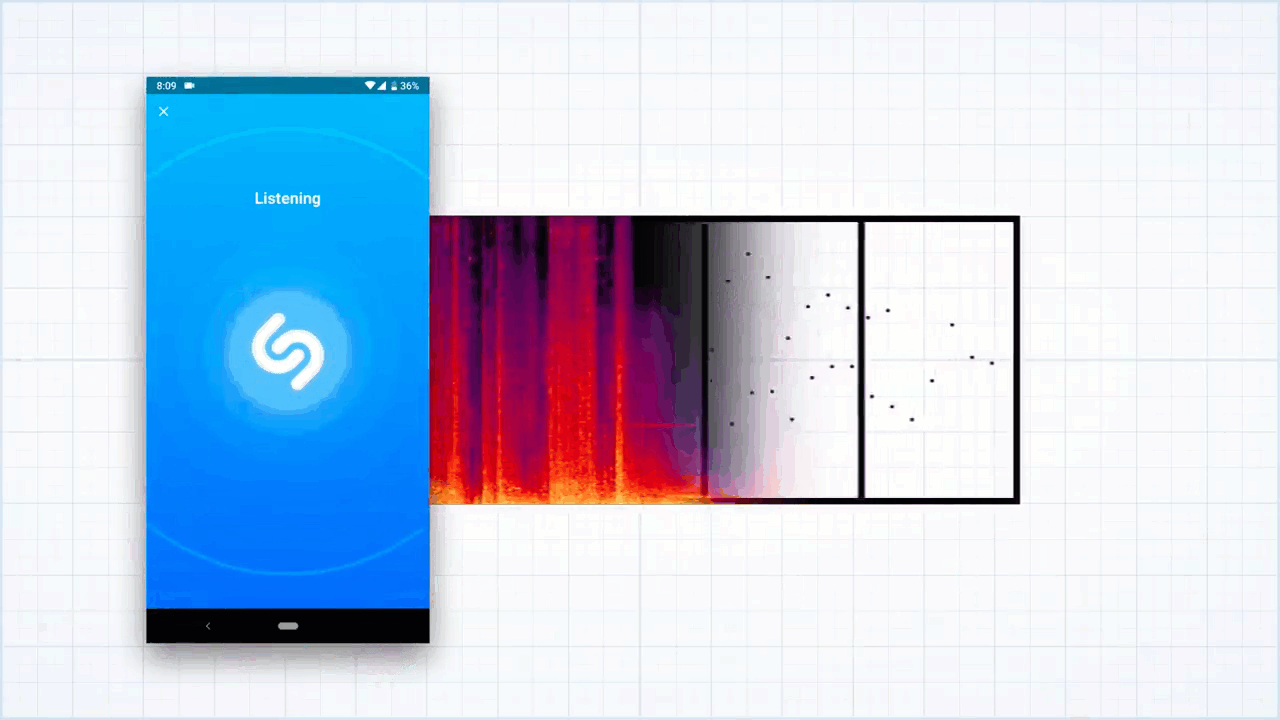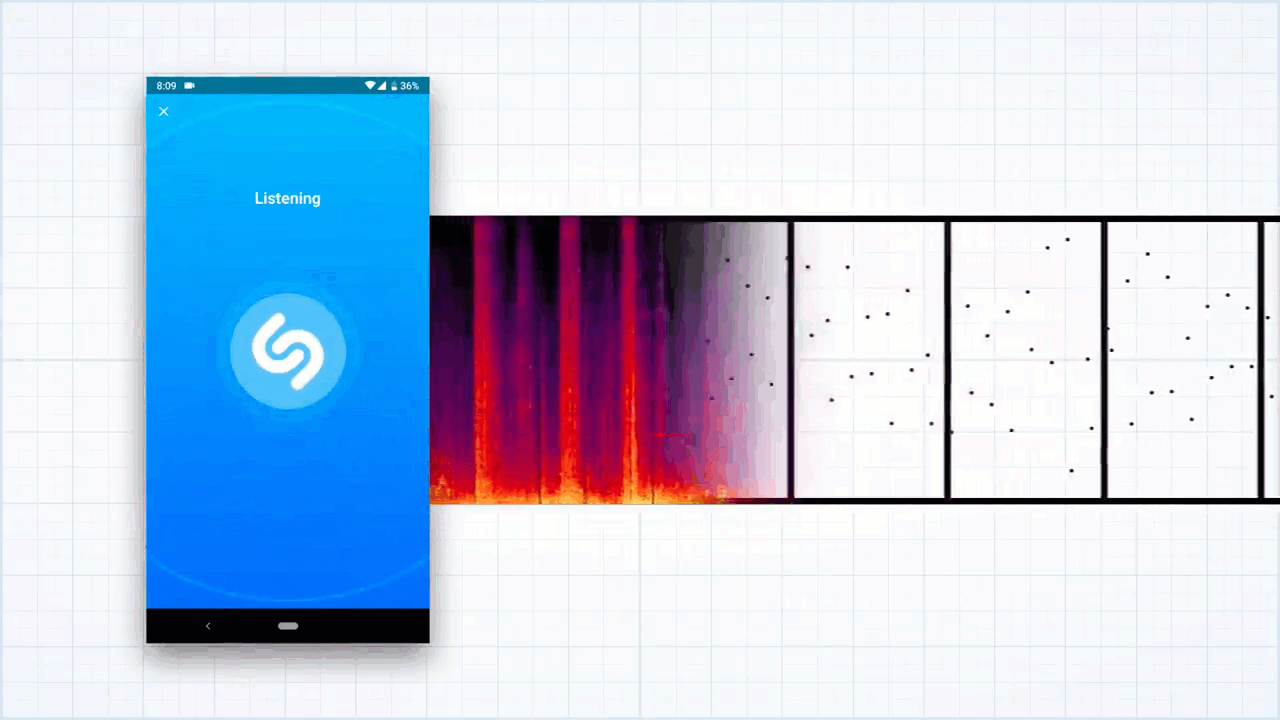
იმისათვის, რომ აღნიშნული ინფორმაცია კომპიუტერისთვის ადვილად "აღქმადი" გავხადოთ, საჭიროა, რომ ის როგორმე შევამციროთ და შევამსუბუქოთ. ქვედა სურათზე კი სწორედ გადამუშავებულ სპექტროგრამას ვხვდებით, რომელსაც სიმღერის ე.წ. ანაბეჭდი შეგვიძლია ვუწოდოთ.
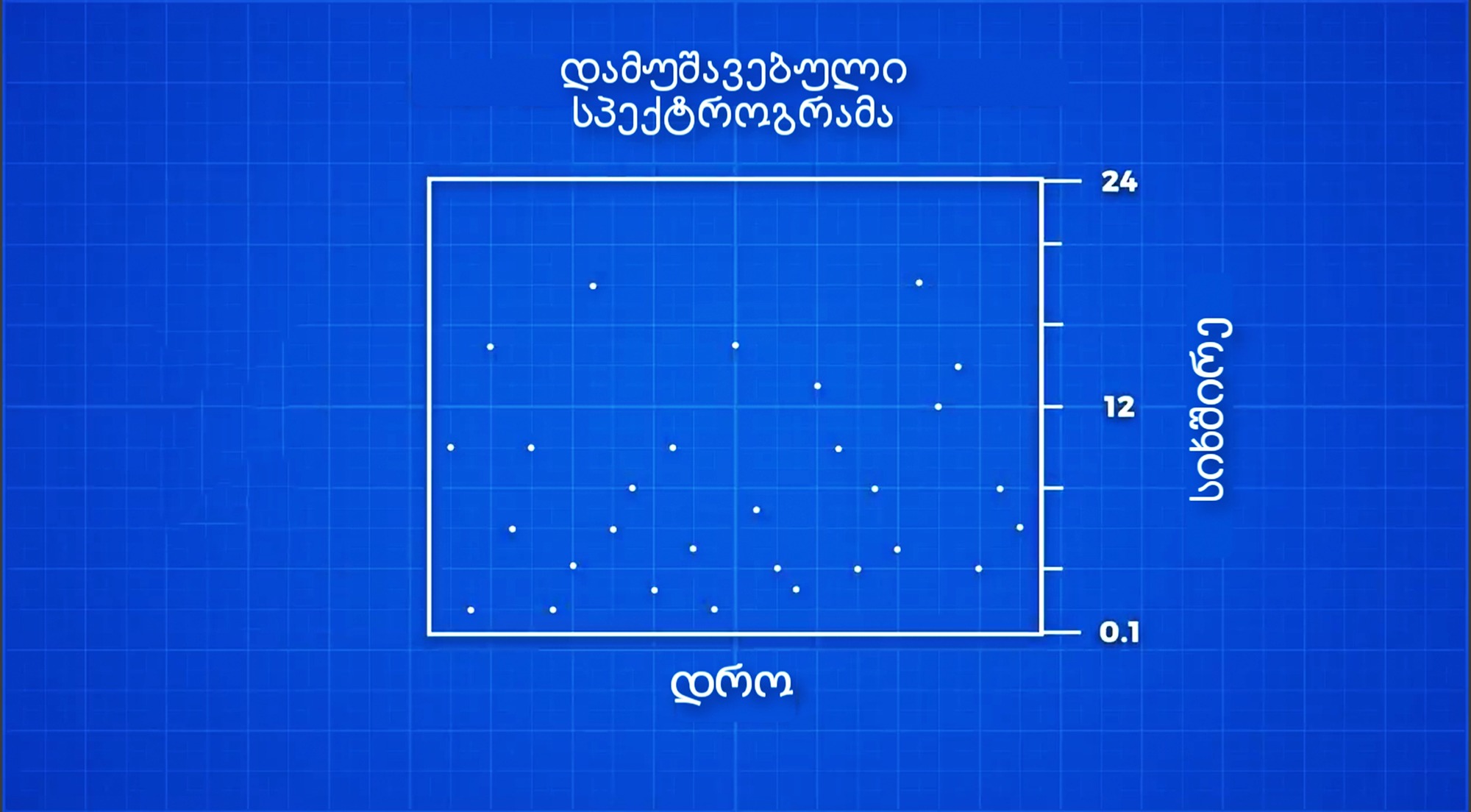
დამუშავებულ ფოტოზე ხედავთ, რომ სიმღერის სპექტროგრამა ერთგვარ ორგანზომილებიან რუკად არის გადაქცეული. ამ რუკას პროგრამა ავტომატურად ქმნის, თითოეული მონიშნული წერტილი შეიძლება რომელიმე ნოტს, სიხშირის პიკს, ან სიმღერის რაიმე მომენტს შეესაბამებოდეს და ისინი ახლა არა სამი განზომილებით, არამედ მხოლოდ ორით, x-ღერძითა და y-ღერძით ხასიათდება.
2. მარტივად ახსნილი ალგორითმი
წინა პუნქტში ჩვენ შევქმენით სიმღერის ერთგვარი რუკა (ანაბეჭდი), რომელიც ამ სიმღერის უნიკალურია. საკმარისია, შევქმნათ ასეთი რუკების მონაცემთა ბაზა, შემდეგ კი ალგორითმს დავავალოთ, რომ მიკროფონით ჩაწერილი სიმღერიდან შექმნილი ანაბეჭდის ასლი მონაცემთა ბაზაში მოძებნოს. თუმცა არსებობს ერთი პრობლემა, ზემოთ მოცემული ანაბეჭდი დროზე, ანუ x-ღერძზეა დამოკიდებული.
მაგალითისთვის, მასზე სამი წერტილი მოვნიშნოთ, ჩვენ ვხედავთ, რომ ერთ-ერთი მათგანი სიმღერის დაწყებიდან მე-3 წამზე გვხვდება, მეორე მე-5-ზე, მესამე კი მე-8-ზე. იმისათვის, რომ ეს რუკა რამეში გამოსადეგი იყოს, საჭიროა, რომ მასში დრო არ იცვლებოდეს, რაშიც ვგულისხმობ შემდეგს: თუ სიმღერას არა დასაწყისიდან (0 წამიდან), არამედ ერთი წამის დაგვიანებით ჩავრთავ, აღნიშნულ რუკაზე ყველა წერტილის x-ღერძის მნიშვნელობა ერთით უკან გადმოინაცვლებს. ანუ იმის მიხედვით, თუ რომელი წამიდან ჩავრთავთ სიმღერას, წერტილების x-ღერძის მონაცემი სხვადასხვა იქნება.
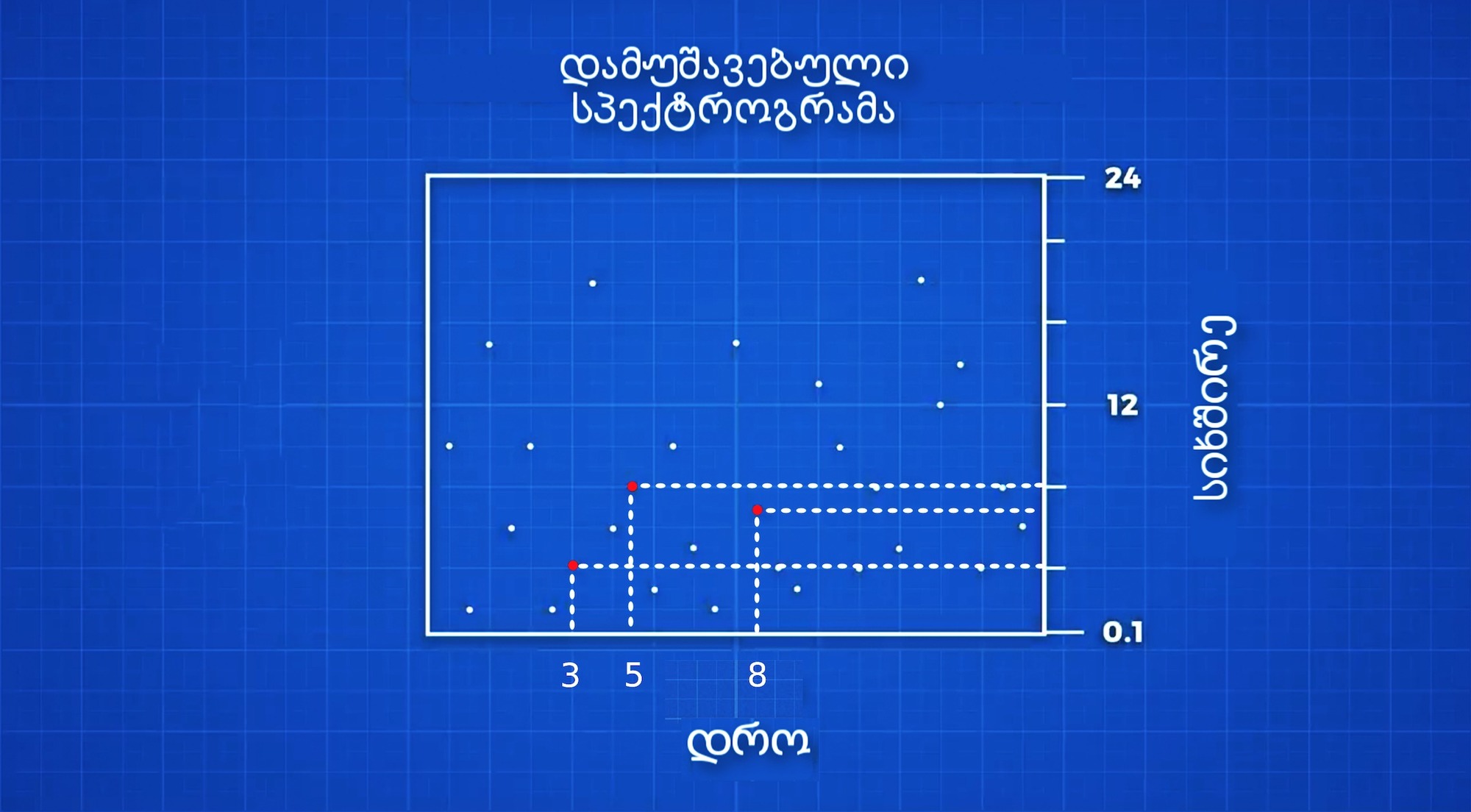
შესაბამისად, შეგვიძლია ერთი სრული სიმღერის ანაბეჭდი შევქმნათ, დასაწყისიდან ბოლომდე, და ის შაზამის მონაცემთა ბაზაში მოვათავსოთ, თუმცა ამ შემთხვევაში შაზამი სიმღერის ამოცნობას მხოლოდ მაშინ შეძლებს, თუ მას სიმღერას დასაწყისიდან მოვასმენინებთ. რადგან თუ სიმღერას რამდენიმე წამით გვიან ჩავრთავთ, წერტილების x-ღერძის მახასიათებელი შაზამის მონაცემთა ბაზაში არსებულ მახასიათებლებს აღარ დაემთხვევა - იქ ყველა წერტილი რამდენიმე წამით წინ, ან უკან იქნება.
ჩვენ კი ვიცით, რომ პროგრამას სიმღერის ამოცნობა ნებისმიერი წამიდან შეუძლია.
შესაბამისად იმისათვის, რომ პროგრამამ სიმღერის ნებისმიერი მონაკვეთის მოსმენისას იმუშაოს, ორგანზომილებიან რუკაზე მოცემული ინფორმაციიდან უნდა შევქმნათ ისეთი მახასიათებელი, რომელიც სიმღერის ხანგრძლივობაზე დამოკიდებული არ იქნება.
ამისათვის, შეგვიძლია მახასიათებლად არა წერტილების x-ღერძთან მიმართება, არამედ წერტილების ერთმანეთთან მიმართება ავიღოთ.
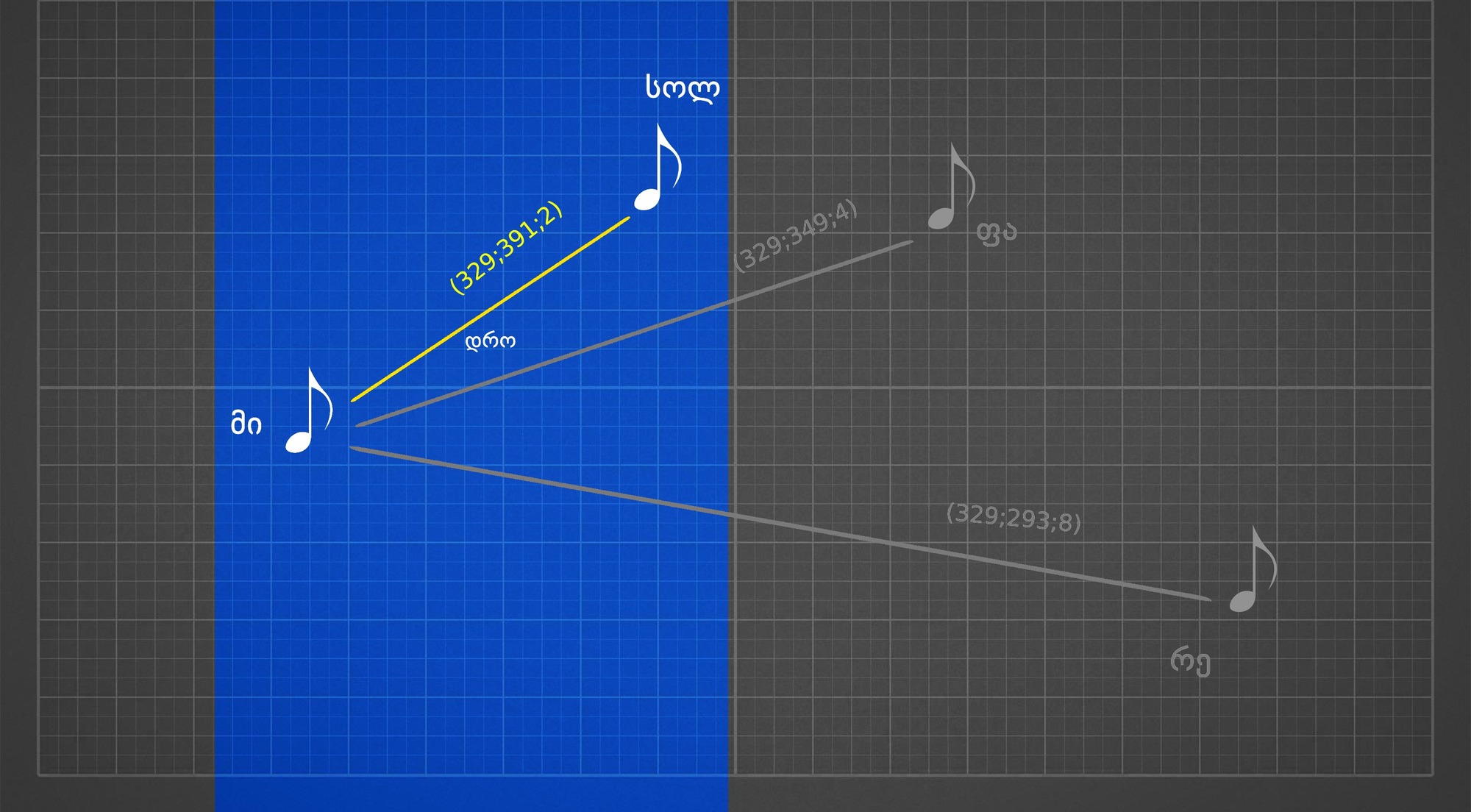
ქვემოთ ხედავთ, რომ ერთ-ერთი წერტილი მის მახლობელ წერტილებთანაა დაკავშირებული. შაზამის ალგორითმი ერთ წერტილს მის მომდევნო მეზობელ წერტილებთან აერთებს, ისევე, როგორც ეს ქვემოთ მოცემულ სურათზეა ასახული.
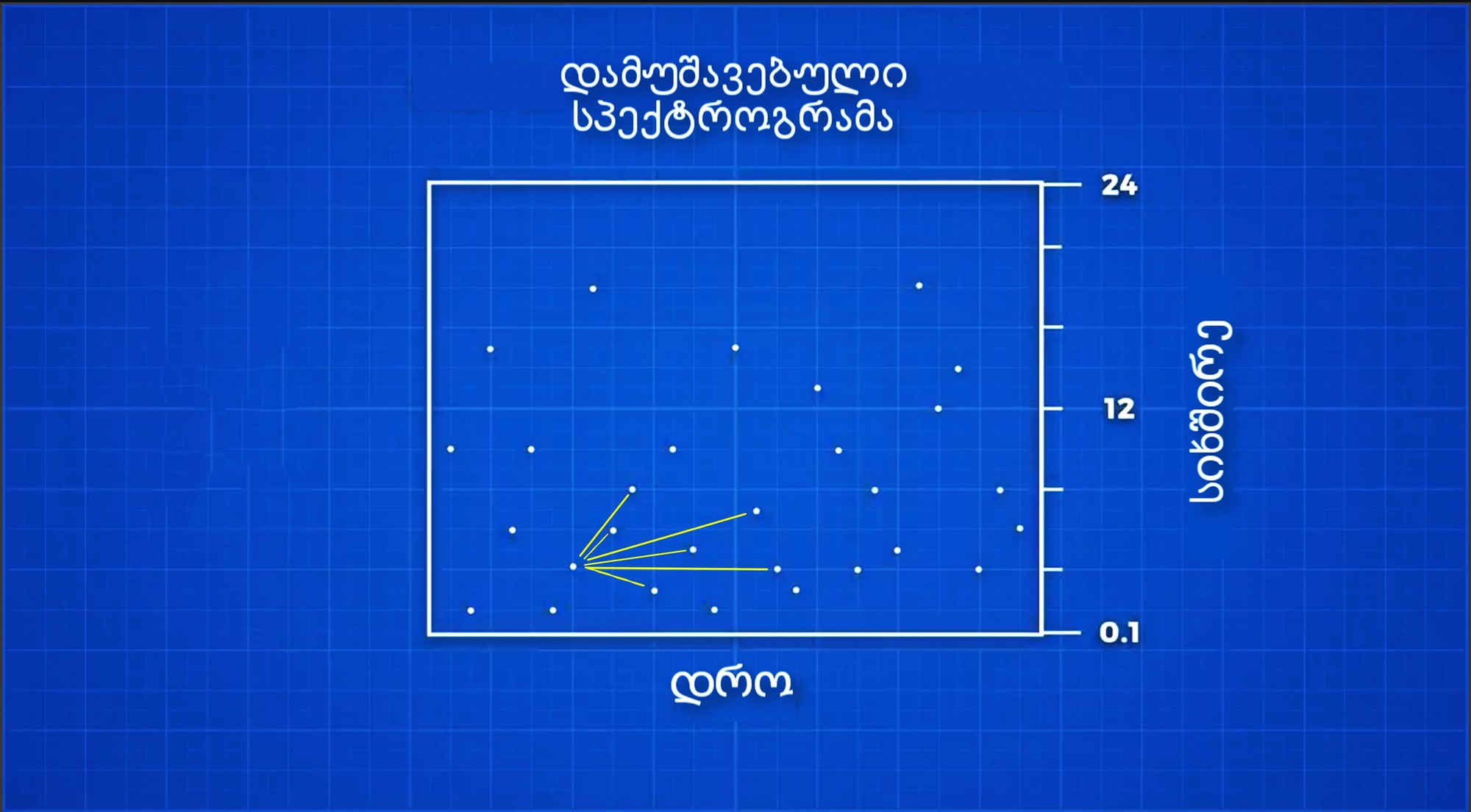
წერტილებს შორის არსებულ დამაკავშირებელ ხაზებს კი შეგვიძლია ჰეში ვუწოდოთ. ჰეში ამ შემთხვევაში სხვა არაფერია, თუ არა ორი კონკრეტული სიხშირის ნოტი, რომლებიც ერთმანეთისგან გარკვეული დროითაა დაშორებული.
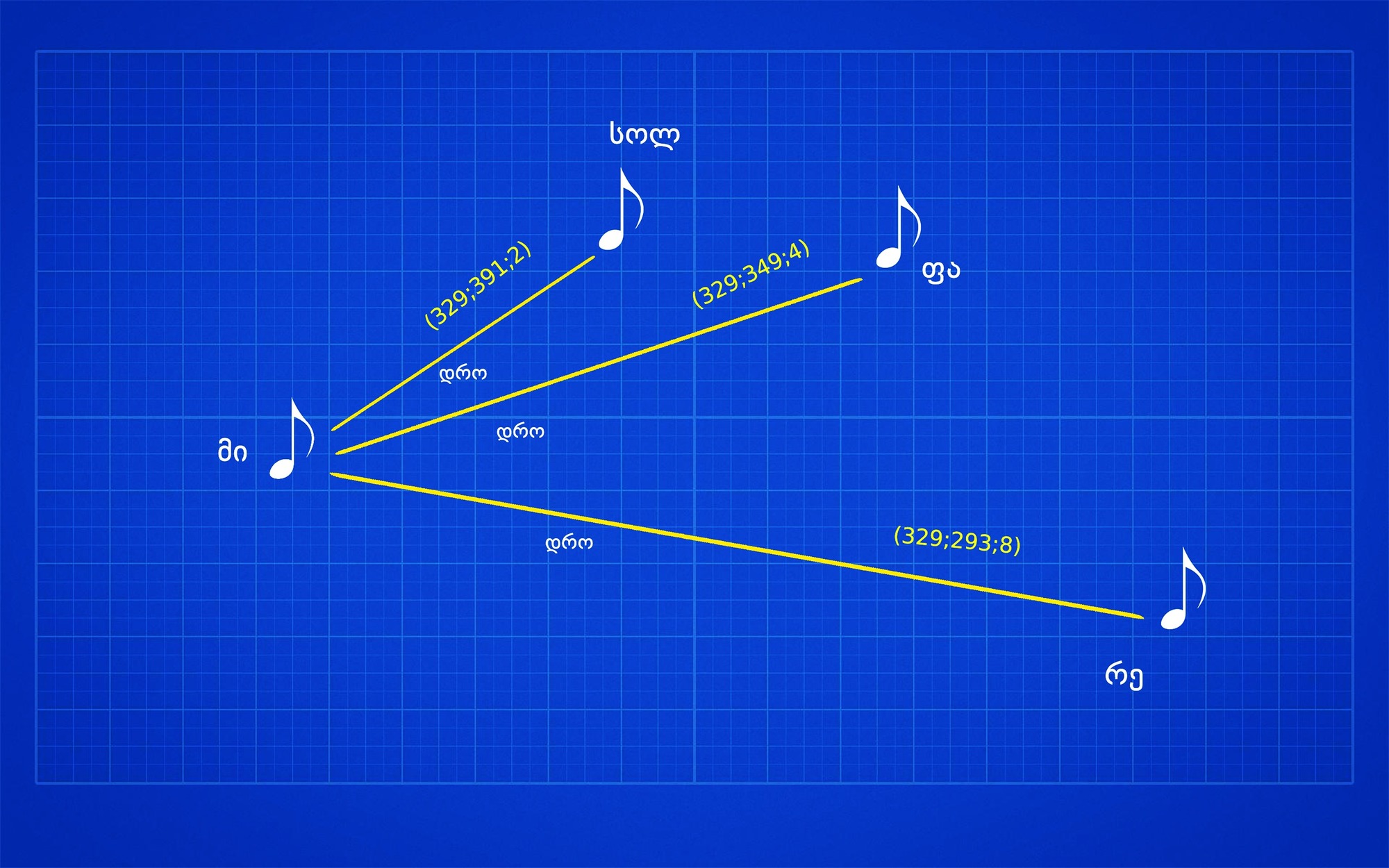
ზემოთ მოცემული თითოეული კავშირის აღწერა კი სულ რაღაც სამი მახასიათებლით შეიძლება: საწყისი ნოტის სიხშირე, მიერთებული ნოტის სიხშირე და მათ შორის არსებული დრო.
ამ სამი მახასიათებლის ჩაწერა კი ძალიან კომპაქტურად ხდება, მაგალითად, მი-ს სიხშირე 329 ჰერცს შეესაბამება, სოლ-ის კი 391-ს, ამ ორ ნოტს შორის კი 2-წამიანი დაშორებაა, შესაბამისად, ამ ორ ნოტს შორის არსებული კავშირი შეიძლება შემდეგი უნიკალური ჰეშით აღიწეროს: (329,391,2)
როგორც ვხედავთ აღნიშნული წერტილი რამდენიმე სხვადასხვა მანძილით დაშორებულ წერტილთანაა დაკავშირებული, ეს ნიშნავს, რომ შაზამს სიმღერის ამოსაცნობად მისი სრულად მოსმენა არ მოუწევს.
ჩავთვალოთ, რომ შაზამმა ჩვენი 4-ნოტიანი სიმღერის მხოლოდ ორ ნოტს მოუსმინა, ამ შემთხვევაში ალგორითმი ერთ-ერთ ნოტთან დაკავშირებულ, ამ სიმღერისთვის უნიკალურ ჰეშს მაინც ამოიცნობს. შესაბამისად, ზედა პუნქტში არსებული პრობლემა, როდესაც სიმღერის სხვადასხვა წამიდან ჩართვა მონაცემის ცვლილებას იწვევდა, აღარ არსებობს.
3. ცოტა მათემატიკა
თუ ჩვენ გვაქვს სიმღერის ჩანაწერი, რომელსაც A ეწოდება და ასევე გვაქვს სიმღერის ნაწყვეტის ჩანაწერი - A', შეგვიძლია ვთქვათ, რომ A' არის A-ს ქვესიმრავლე (A'⊂A)
თუ ჩვენ შაზამის ალგორითმს A-ს მოვასმენინებთ, მივიღებთ ჰეშების გარკვეულ რაოდენობას, რომელთაგანაც თითოეული მათგანი ამ სიმღერის კონკრეტულ ადგილს შეესაბამება. ხოლო თუ შაზამის ალგორითმს A-ს ნაწყვეტს, ანუ A'-ს მოვასმენინებთ, მივიღებთ ჰეშს, რომელიც A-ს ქვესიმრავლეა.
ეს შაზამის ალგორითმის უმნიშვნელოვანესი კომპონენტია.

მას შემდეგ, რაც შაზამი სიმღერას მთლიანად მოუსმენს და მისგან ჰეშების გენერირებას მოახდენს, სისტემა აღნიშნულ ინფორმაციას მონაცემთა ბაზაში ერთ კონკრეტულ ადგილას ინახავს, მაგალითად, წარმოიდგინეთ საქაღალდე, რომელსაც ამ სიმღერის სახელწოდება ჰქვია, მასში კი ამ სიმღერის შესაბამისი ჰეშებია შენახული.
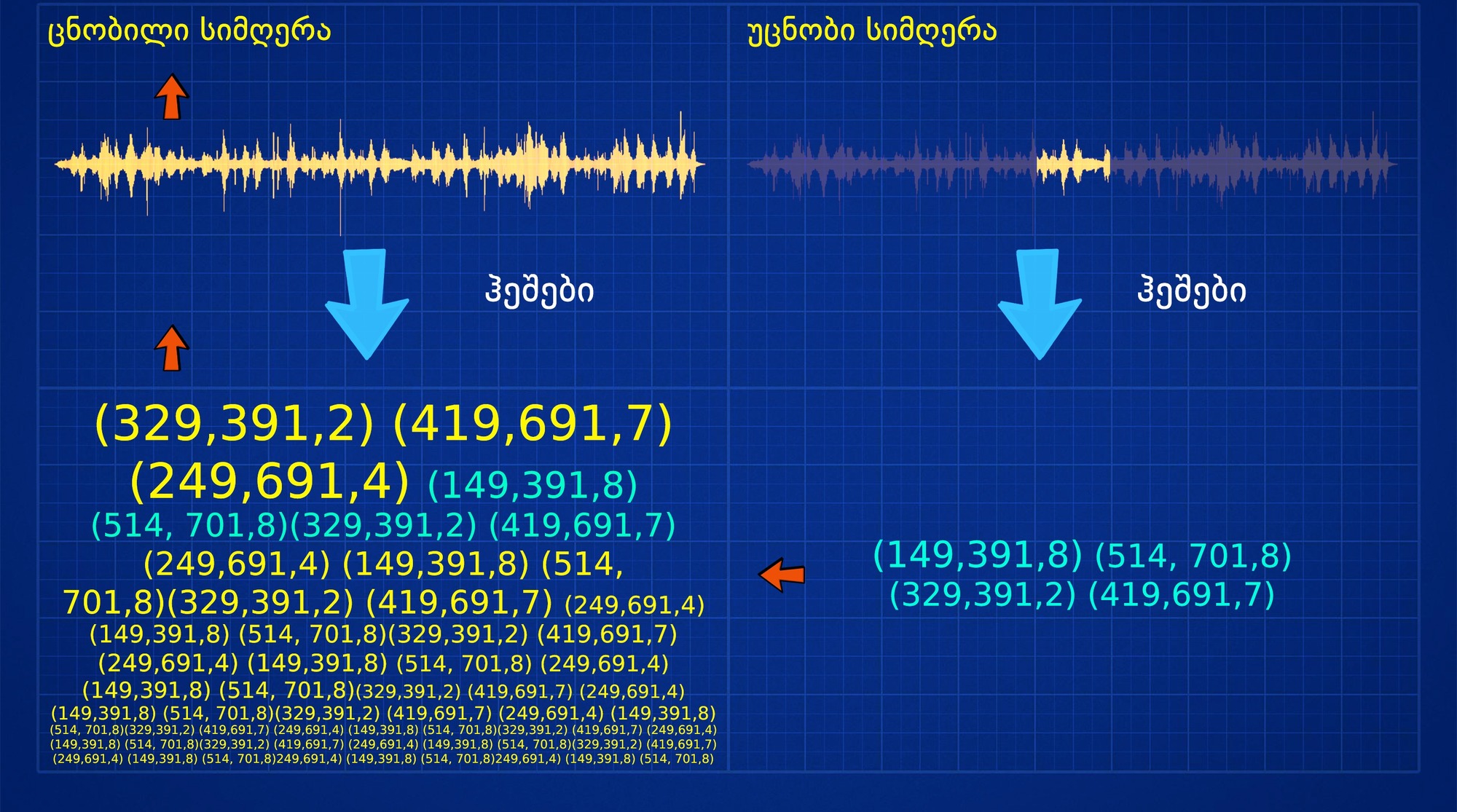
შემდეგ, როდესაც თქვენ შაზამს გამოიყენებთ და მას მუსიკის ნაწყვეტს მოასმენინებთ, აპლიკაცია ამ ნაწყვეტის შესაბამისი ჰეშების გენერირებას მოახდენს, რომელთა ასლებიც მონაცემთა ბაზაში იმავე საქაღალდეში ინახება, სადაც მთლიანი სიმღერა.
შემდეგ კი ისღა დაგვრჩენია, რომ მოვძებნოთ, თუ რომელ საქაღალდეშია აღნიშული ჰეშები, რის შემდეგაც სიმღერის სახელწოდება ნათელი ხდება.
იმის ასახსნელად, თუ როგორ ახდენს სისტემა ჰეშების ადგილმდებარეობის სწარაფად დადგენას, კიდევ ერთი დიდი სტატიის წაკითხვა იქნება საჭირო, რითიც ამჟამად თავს არ შეგაწყენთ.
დავამატებ, რომ აღნიშნული სისტემის მუშაობისთვის საჭიროა სიმღერების უზარმაზარი მონაცემთა ბაზის ქონა, რომლის შექმნაშიც შაზამის გუნდმა დიდი ძალისხმევა ჩადო.
შაზამმა თავდაპირველად პარტნიორობა სადისტრიბუციო კომპანია Entertainment UK-სთან წამოიწყო და ლომპანიას მათ მფლობელობაში არსებული 1,5 მილიონი სიმღერის ციფრულ ფორმატში გადაყვანა შესთავაზა, რითიც შაზამის პირველი მონაცემთა ბაზა შეიქმნა. მას შემდეგ კომპანიამ ურთიერთობა მრავალ ჩამწერ სტუდიასთან გააფორმა, რათა მათ მიერ გამოცემული სიმღერების შაზამის მონაცემთა ბაზაში დამატება მომხდარიყო.
2013 წელს შაზამმა პარტნიორობა ელექტრონული მუსიკის ინტერნეტ მაღაზიასთან, Beatport-თანაც დაიწყო, რომლის მეშვეობითაც შაზამს უკვე ელექტრონული მუსიკის ამოცნობაც ეფექტურად შეუძლია.
სიმღერების ამოცნობის ამ ჭკვიანური ხერხის შექმნის შედეგად კომპანია 2017 წელს Apple-მა 400 მილიონ დოლარად შეიძინა.
ასე რომ, მომავალში, როცა აპლიკაციას მელოდიას მოასმენინებთ და ის რამდენიმე წამში დაგიბრუნდებათ სიმღერის სახელით, გეცოდინებათ, რომ საქმე ციფრულ ჯადოქრობასთან გაქვთ.









კომენტარები