
0
წაკითხვა
0
კომენტარი
0
გაზიარება
ხელოვნური ინტელექტი თუ "მაგია"
არც ისე ბევრი წლის წინ ხელოვნური ინტელექტის გაგონებაზე ყველას რობოტი წარმოგვიდგებოდა თვალწინ, თუმცა დღეს ეს ტერმინი გაცილებით მრავლისმომცველია და ჩვენ ირგვლივ მისი არსებობა რობოტის დანახვის გარეშეც ადვილად შესამჩნევია.
მაგალითად, მეგობარმა გაზქურის შერჩევაში დახმარება გთხოვა, შენ უბრალოდ დასერჩე და მას შემდეგ ყველგან გაზქურის რეკლამები გტანჯავს, ვიდრე ალგორითმი არ მიხვდება, რომ გაზქურები აღარ გაინტერესებს და დროა სხვა რამეზე გადაერთოს. როცა მსგავსი რამ პირველად გემართება ფიქრობ, რაღაც მაგიურთან უნდა გვქონდეს საქმე, მაგრამ მერე აღმოაჩენ, რომ ეს "მაგია" ფეისბუქის, გუგლის, იუთუბის და ა.შ ალგორითმებს უკავშირდება. კი, ისინი გვითვალთვალებენ, აკვირდებიან რას ვეძებთ, ვკითხულობთ, ვუყურებთ და ანალიზის შედეგად სწავლობენ რა გვაინტერესებს. მთელი ამ პროცესის მიზანი კი მოპოვებულ ინფორმაციაზე დაყრდნობით იმის პროგნოზირებაა თუ რამ შეიძლება დაგვაინტერესოს მომავალში.
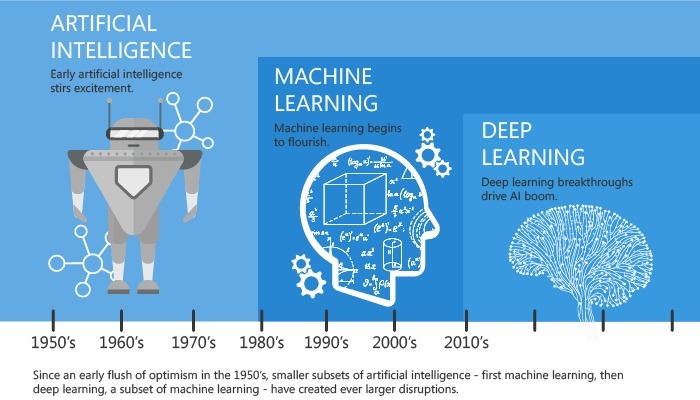
ხელოვნური ინტელექტის ქვემიმართულებები
დაახლოებით გასაგებია რას სწავლობენ. მაგრამ ვინ სწავლობს? მარტივი მისახვედრია, რომ ამდენ ინფორმაციას ადამიანი ვერასდროს დაამუშავებს, მაგრამ მსგავსი ტექნიკური მისიების შესასრულებლად ყველაზე კარგი რაც ჯერჯერობით გაგვაჩნია — კომპიუტერია. მანქანური სწავლების ინჟინრები მას გადასცემენ სხვადასხვა წყაროებიდან მოპოვებულ აურაცხელი რაოდენობის მონაცემებს, ხოლო დანარჩენს ეს ელექტრო მოწყობილობები აკეთებენ და ადამიანივით სწავლისა და აზროვნების მოდელირებას ახდენენ. სწორედ ამიტომ ჰქვია ხელოვნურ ინტელექტს — ხელოვნური ინტელექტი და მის ერთ-ერთ განშტოება მანქანურ სწავლებას — მანქანური სწავლება (machine learning, ML), რომელზეც ამ სტატიაში უფრო მეტს მოგიყვებით.
როგორ სწავლობენ მანქანები?
ტერმინი "მანქანური სწავლება" ხელოვნური ინტელექტისა და კომპიუტერული თამაშების პიონერს — არტურ სამუელს ეკუთვნის. სამუელმა შექმნა პროგრამა, რომელსაც შაშის თამაში შეეძლო. რაც უფრო მეტს თამაშობდა პროგრამა მით უფრო მეტს სწავლობდა წინარე გამოცდილებიდან და ძლიერდებოდა იმის ხარჯზე, რომ ნანახი ჰქონდა ქვების მრავალი სხვადასხვა განლაგება, ასეთ სიტუაციაში გაკეთებული სვლები და მისი მოტანილი წარმატება ან წარუმატებლობა, რაც თამაშისას სწორი გადაწყვეტილების მიღებაში ეხმარებოდა.
ხელოვნური ინტელექტის ერთ-ერთი მთავარი პრობლემა მონაცემების ნაკლებობაა. რაც მეტია მონაცემების რაოდენობა, მით უფრო ზუსტი და წარმატებულია მანქანური სწავლების მოდელი. თუმცა მეორე მხრივ, მონაცემების რაოდენობის ზრდასთან ერთად რთულდება მისი დამუშავება. განსაკუთრებით, თუ საქმე გვაქვს რთული არქიტექტურის ხელოვნურ ნეირონულ ქსელებთან, მის გაწვრთნას (ანუ სწავლებას) შესაძლოა რამდენიმე დღე და თვეც კი დასჭირდეს. დროის ფაქტორთან ერთად მნიშვნელოვანია ადექვატური გამოთვლითი სიმძლავრის უზრუნველყოფაც.
მონაცემების შეგროვებას კი მთელი რიგი მტკივნეული მომენტები ახლავს. ვინაიდან ეს პროცესი ავტომატიზირებულია, გარკვეული წყაროდან კომპიუტერის მეშვეობით ერთბაშად შეგროვებულ მონაცემებს ხშირად "ნაგავიც" მოყვება, თუმცა უკეთესი გზა სამწუხაროდ არ არსებობს. ასეთი რაოდენობის მონაცემების ადამიანის მიერ მექანიკურად შეგროვებას (რაც ფაქტობრივად შეუძლებელია) ისევ კომპიუტერის მიერ შეგროვებულის "გაწმენდას" ვამჯობინებთ.
რას ნიშნავს ნაგავი? მაგალითად, თუ გვინდა ადამიანთა მიერ შევსებული აპლიკაციების დამუშავება, შესაძლოა ზოგიერთი მათგანი ნახევრად შევსებული აღმოჩნდეს და დატოვებულ ცარიელ უჯრებთან სხვადასხვა გზით მოგვიწიოს გამკლავება. გარდა ამისა, როგორ დავამუშავებთ ასაკს როგორც რიცხვით მონაცემს თუ ვინმეს ციფრების გარდა შემთხვევით ან განზრახ სხვა სიმბოლოზეც მოუხვდა ხელი (მაგ. ასაკი შეიყვანა როგორც 23/). მართალია, მსგავსი შემთხვევების ასარიდებლად მონაცემთა ვალიდაციის ფუნქცია აპლიკაციაში თავიდანვე ჩაშენებულია, რაც მომხმარებელს მსგავსი შეცდომების დაშვების შესაძლებლობას არ აძლევს, თუმცა ყველაფრის წინასწარ გათვლა ხშირად რთულია და თანაც ეს მხოლოდ მარტივი სადემონსტრაციო მაგალითი იყო. სხვა ტიპის მონაცემთა წყაროებს კი კიდევ მრავალი პრობლემა შეიძლება ახლდეს.
შემდეგ, რამდენადაც ეს შესაძლებელია, ხდება მონაცემების ზედაპირული შესწავლა სხვადასხვა სტატისტიკურ მონაცემებზე დაკვირვებითა და ვიზუალიზაციის საშუალებით, რაც გვეხმარება განვსაზღვროთ თუ რა ტიპის მონაცემებთან გვაქვს საქმე, რა დამოკიდებულება შეიძლება არსებობდეს მათ შორის და მანქანური სწავლების რომელი მოდელი შეიძლება მოერგოს მას. ზოგჯერ კი მონაცემები იმდენად რთულია, რომ ვერც ამის განსაზღვრა ხერხდება, რაც იძულებულს გვხდის, ვცადოთ რამდენიმე სხვადასხვა ვარიანტი და დავტოვოთ ის მოდელი, რომელიც ყველაზე კარგ შედეგს აჩვენებს. მაგრამ როგორ განვსაზღვრავთ რამდენად კარგი ან ცუდია მისი შედეგი?
როგორც წესი, მონაცემები იყოფა ორ ნაწილად. ერთი ნაწილი (დაახლოებით 70%, თუმცა რაიმე შეთანხმებული წესი არ არსებობს და დამოკიდებულია მანქანური სწავლების ინჟინრის გადაწყვეტილებაზე) მოდელის გასაწვრთნელად გამოიყენება, ხოლო დანარჩენს უკვე გაწვრთნილი მოდელის ტესტირებისთვის ვინახავთ. როგორც აღვნიშნეთ, მანქანური სწავლება რაღაც შემავალი მონაცემების (input) მიხედვით, გარკვეული შედეგის (output, target) წინასწარმეტყველებას ემსახურება. ამიტომ საწვრთნელ მონაცემებში თავიდანვე მოცემული გვაქვს სხვადასხვა ტიპის input-ების შესაბამისი output მნიშვნელობები, რაზე დაყრდნობითაც ალგორითმმა კარგად უნდა შეისწავლოს ამ ორს შორის არსებული კავშირები და შექმნას "შავი ყუთი", რომელშიც მომავალში შევიყვანთ მხოლოდ input-ს, რომლის შესაბამისი output ჩვენთვის უცნობია, მაგრამ მას უკვე "შავი ყუთიდან" გამომავალი შედეგის სახით მივიღებთ. სწორედ ეს "შავი ყუთია" მანქანური სწავლების მოდელი.
ცხადია, მოდელი ყოველთვის ზუსტ პასუხს ვერ დაგვიბრუნებს, თუმცა რადგან ხშირად ზუსტთან მიახლოებული ინფორმაციის მიღებაც უმნიშვნელოვანესი შედეგია, ამ კომპრომისსაც ვთანხმდებით. მაგრამ როგორ გავიგოთ, რომ მიახლოებული მაინც იქნება? ან რამდენად მიახლოებული? სწორედ ამისთვის გამოიყენება "გადანახული" მონაცემები. სატესტო მონაცემებს "მოვაჭრით" იმ მნიშვნელობებს რომლის პროგნოზისთვისაც ჩვენი მოდელია შექმნილი და დარჩენილ ნაწილს input -ის სახით მივაწვდით მოდელს, თითქოს არ ვიცით ამ მონაცემების შესაბამისი პასუხი და ვთხოვთ, თავისი ვარაუდი შემოგვთავაზოს. მის მიერ დაბრუნებულ ვარაუდებს კი ჩვენ მიერ "მოჭრილ" მნიშვნელობებს, ანუ რეალურ პასუხებს ვადარებთ, რაც მისი სიზუსტის შეფასების საშუალებას გვაძლევს.
ასევე იხილეთ: ღრმა დასწავლის რევოლუციის 10 წელი — აჟიოტაჟი თუ ფუნდამენტური ძვრა
ადამიანის ტვინიც სწორედ ამ პრინციპით მუშაობს. თქვენც შეგიძლიათ იწინასწარმეტყველოთ ბინის მიახლოებითი ფასი თუ შემავალი მონაცემების სახით მიიღებთ ინფორმაციას მისი ადგილმდებარეობის, სართულის, ფართობის და სხვა მახასიათებლების შესახებ. თუმცა ეს წინასწარმეტყველება გაცილებით უფრო მიახლოებული იქნებოდა რეალურთან თუ თქვენ მაკლერი იქნებოდით. რატომ? განსვავება მხოლოდ გამოცდილებაში, ანუ სატრენინგო მონაცემების სიმრავლეშია. ვინაიდან მაკლერს უამრავი ბინა უნახავს სხვადასხვა მახასიათებლებითა და მისი შესაბამისი ფასებით, ის გაცილებით უკეთ ხედავს თუ რა დამოკიდებულებაა ამ ორს შორის და როგორ ცვლის თითოეული მახასიათებლის ცვლილება შედეგს, ანუ ბინის ფასს. ამ ცვლილების აღმწერ საშუალებებს კი ფორმალურ ენაზე პარამეტრები ეწოდება, რომელიც მოდელის "შავ ყუთში" არსებულ ფუნქციას ან ფუნქციების ერთობლიობას (გართულებული მოდელის შემთხვევაში) განსაზღვრავს. სწავლების პროცესში კი ხდება ამ პარამეტრების ოპტიმიზაცია, ანუ ისე შერჩევა, რომ როდესაც ამ ფუნქციებს მახასიათებელთა მნიშვნელობებს გადავცემთ, მოდელმა აჩვენოს შესაძლო ყველაზე კარგი შედეგი ვარაუდების რეალობასთან სიახლოვის თვალსაზრისით. სწავლების პროცესის შემდეგ დარჩენილ ცოდნასაც სწორედ ამ პარამეტრების ოპტიმალური მნიშვნელობები წარმოადგენს.
მანქანური სწავლების ფორმები
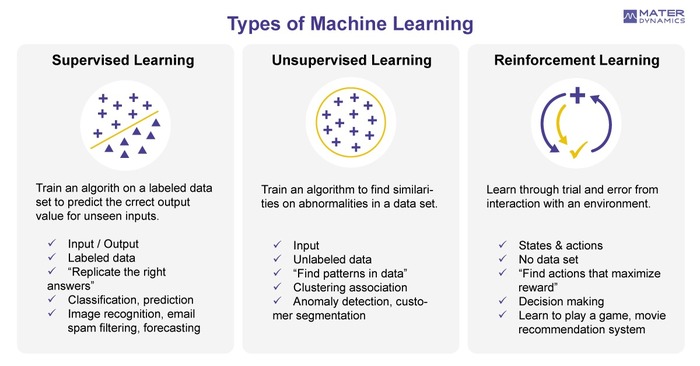
მასწავლებლით, მასწავლებლის გარეშე და დაჯილდოებით სწავლება
იმის მიხედვით, თუ რა ტიპის პრობლემასთან გვაქვს საქმე, გამოყოფენ მანქანური სწავლების სამ ძირითად მიდგომას: სწავლება მასწავლებლით (supervised learning), მასწავლებლის გარეშე (unsupervised learning) და სწავლება დაჯილდოებით (reinforcement learning).
ჩვენ მიერ ზემოთ განხილული ბინის ფასის პროგნოზირების მაგალითი სწორედ მასწავლებლით სწავლების მიდგომას განეკუთვნება. ანუ ეს ის შემთხვევაა, როცა მოდელს გაწვრთნისას წინასწარ აქვს მიღებული ინფორმაცია ბინის მახასიათებლებისა და შესაბამისი ფასის შესახებ და გვაქვს რეგრესიის ამოცანა, რაც ნიშნავს, რომ აქამდე "უნახავი" ბინისთვის, მის მახასიათებლებზე დაყრდნობით, მოდელმა ფასის პროგნოზირება უნდა შეძლოს. მასწავლებლით სწავლება გამოიყენება კლასიფიკაციის ამოცანების გადასაჭრელადაც. თუ ბინის ფასი ფართობთან, სართულთან, ადგილმდებარეობასთან და ა.შ ერთად გვექნებოდა მოცემული, როგორც ერთ-ერთი მახასიათებელი და საჭირო იქნებოდა ამ მონაცემებზე დაყრდნობით დასკვნის გაკეთება თუ მოცემული სამი კლასიდან — "ძვირი", "საშუალო", "იაფი" — რომელს მიეკუთვნება მოცემული ბინა, ეს უკვე კლასიფიკაციის ამოცანა იქნებოდა.
მასწავლებლის გარეშე სწავლებისას კი მოდელისთვის ცნობილია მხოლოდ ბინის მახასიათებლები და არანაირ ინფორმაციას არ ფლობს მისი ფასის შესახებ. მაშინ როგორ შეიძლება მოდელმა ასეთ დროს ფასის პროგნოზირება შეძლოს? რაზე დაყრდნობით? დიახ, რა თქმა უნდა, ეს შეუძლებელია. ამიტომაც, მასწავლებლის გარეშე სწავლება სხვა ტიპის პრობლემებისთვისაა განკუთვნილი. მაგალითად, როცა გადასაჭრელია კლასტერიზაციის ამოცანა, რაც გულისხმობს, რომ ჩვენ ვფლობთ ინფორმაციას ბინის სხვადასხვა მახასიათებლების შესახებ, რის მიხედვითაც გვინდა მათი კლასტერიზაცია, ანუ რაღაც თვალსაზრისით ერთნაირი მონაცემების ერთად დაჯგუფება, იმდენ კლასად რამდენსაც მივუთითებთ.
დაჯილდოებით სწავლება (RL) არის უკუკავშირზე დამყარებული მანქანური სწავლების პარადიგმა, რომლის დროსაც აგენტი (კომპიუტერული პროგრამა, კომპონენტი, რომელიც წყვეტს თუ რა მოქმედება შეასრულოს) სწავლობს გარკვეულ გარემოში სხვადასხვა მოქმედებების შესრულებით და თანმდევ შედეგებზე დაკვირვებით. "გონივრული" გადაწყვეტილებების საპასუხოდ ის იღებს დადებით, ხოლო "არაგონივრულის" შემთხვევაში უარყოფით უკუკავშირს. გამოცდილებაზე დაყრდნობით კი აგენტი სწავლობს ოპტიმალური გადაწყვეტილებების მიღებას, რაც საბოლოო ჯამში მაქსიმალურ ჯილდოს მოუტანს. რა თქმა უნდა, ჯილდო პირდაპირი მნიშვნელობით არ უნდა გავიგოთ. მისი მოდელირებაც მათემატიკურად ხდება.
2016 წელს RL-ზე დაფუძნებულმა კომპიუტერულმა პროგრამამ სახელად — AlphaGo, ჩინურ თამაშ Go-ში მსოფლიო ჩემპიონი დაამარცხა. Go-ს დაფაზე ქვების განლაგების 10^170 სხვადასხვა კონფიგურაცია არსებობს (მეტი ვიდრე ატომების რაოდენობა ჩვენთვის ცნობილ სამყაროში), რაც თამაშს ძალიან კომპლექსურს ხდის. ისევე როგორც ადამიანმა, თამაში AlphaGo-მაც პროფესიონალ მოთამაშეებთან ათასობით შერკინების შედეგად მიღებულ გამოცდილებაზე დაყრდნობით ისწავლა. უახლეს RL-ზე დაფუძნებულ Go აგენტებს კი საკუთარ თავთან თამაშით სწავლაც შეუძლიათ.
ასევე იხილეთ: DeepMind-ის ახალი AI სხვადასხვა თამაშს წესების წინასწარი განსაზღვრის გარეშე ართმევს თავს
RL მიდგომა რეალურ ცხოვრებაშიც შეგვიძლია დავინახოთ, როცა ადამიანი (განსაკუთრებით ბავშვი) გარემოსთან ინტერაქციის შედეგად გამოტანილ დასკვნებზე დაყრდნობით სწავლობს. მაგალითად ეხება ცხელ საგანს, რასაც ახლავს ტკივილი, ანუ უარყოფითი უკუკავშირი, რის შედეგადაც ხვდება, რომ მსგავსი ქმედების განმეორება "წამგებიანი" და ნეგატივის მომტანია.
მანქანური სწავლების ინჟინრის კარიერა
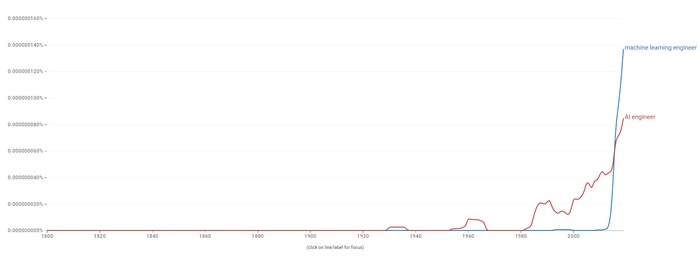
ქვემოთ მოცემულ სურათზე Google ngrams-ის საშუალებით ნაჩვენებია გუგლის მიერ გაციფრულებულ წიგნთა კორპუსში ფრაზების - "machine learning engineer"-სა და "AI engineer"-ის მოხვედრის სიხშირე წლების განმავლობაში. გრაფიკზე ნათლად ჩანს 2012-დან 2019-მდე მათი პოპულარობის ექსპონენციალური ზრდა, რაც, როგორც დღევანდელი მდგომარეობა გვიჩვენებს, არც მომავალში უნდა შენელდეს.
მანქანური სწავლების ინჟინრები ჩვენ მიერ ზემოთ აღნიშნულ საქმიანობას ახორციელებენ. აორგანიზებენ საჭირო მონაცემებს, არჩევენ, წვრთნიან და ტესტავენ შესაბამის მოდელს, რის შედეგადაც ქმნიან ხელოვნურ ინტელექტზე დამყარებულ პროგრამულ უზრუნველყოფას (რომელიც ძირითადად, სხვადასხვა ბიზნეს ამოცანებისთვის გამოიყენება).
პერსპექტიული კარიერა კი, ბუნებრივია, ბევრ შრომასაც მოითხოვს. ML ინჟინრობამდე რამდენიმე სხვადასხვა დისციპლინის დაუფლებაა საჭირო, მათ შორის უმაღლესი მათემატიკა (კალკულუსი), წრფივი ალგებრა, ალბათობის თეორია და სტატისტიკა. ამასთან ერთად კომპიუტერული მეცნიერების ცოდნაც დაგჭირდებათ. ვინაიდან მუდმივად მონაცემებთან გექნებათ საქმე, კარგად უნდა ერკვეოდეთ მონაცემთა ბაზებში, ხოლო იმისთვის, რომ პრობლემის პრაქტიკული გადაწყვეტაც შეძლოთ, ალგორითმული აზროვნება და პროგრამირების ცოდნა დაგჭირდებათ. ხელოვნურ ინტელექტში ყველაზე პოპულარული python პროგრამირების ენაა, რომელსაც მანქანური სწავლებისთვის მრავალი მოქნილი ფრეიმვორკი გააჩნია.
მანქანური სწავლების ინჟინრებზე მოთხოვნა 2015 დან 2018 წლამდე 344%-ით გაიზარდა და 2019 წელს ამერიკაში #1 სამუშაო პოზიციად დასახელდა.
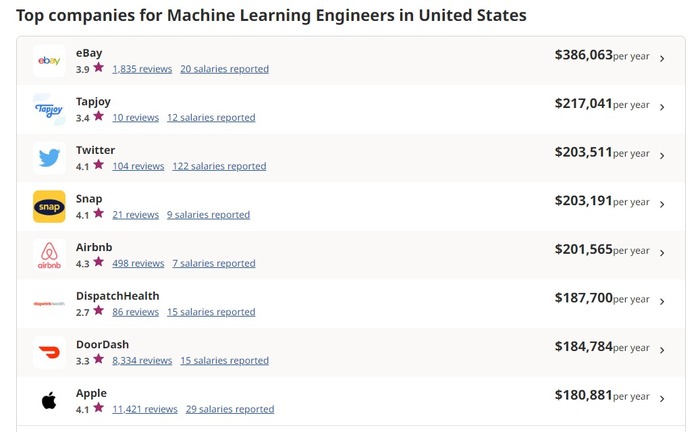
ტოპ კომპანიები მანქანური სწავლების ინჟინერთათვის შეერთებულ შტატებში
Indeed-ის მიხედვით ამერიკაში ML ინჟინრის მინიმალური წლიური ხელფასი 66 460$, მაქსიმალური 250 712$, ხოლო საშუალოდ 129 082$-ს შეადგენს.
საქართველოში ML ინჟინრებზე მოთხოვნა ნაკლებადაა. ამჟამად (ვიდრე მე ამ სტატიას ვწერ) job.ge -სა და hr.ge ვებსაიტებზე მსგავსი ტიპის არცერთი ვაკანსია არ გვხვდება, რაც ალბათ იმითაა გამოწვეული, რომ ქართული კომპანიები არ საჭიროებენ იმდენად კომპლექსური პრობლემების გადაჭრას, რომელიც ხელოვნური ინტელექტის ინტეგრაციას მოითხოვს, თუმცა საზღვარგარეთულ პრაქტიკაზე დაყრდნობით შეგვიძლია ვივარაუდოთ, რომ ეს სიტუაცია საქართველოშიც მალე შეიცვლება და ხელოვნური ინტელექტის გარეშე ბიზნესკონკურენციის დაძლევა ქართული კომპანიებისთვისაც საგრძნობლად გართულდება.










კომენტარები